Wer im Internet viel unterwegs ist, kennt das Problem: überall werden Zugangsdaten benötigt, sei es beim Online-Banking, in Foren, beim Webmailer oder Online-Shops. Das Problem? Wer kann sich all die verschiedenen Passwörter merken?
Ich kenne viele, die sich ein Passwort merken und dieses bei den verschiedenen Diensten, in verschiedenen Variationen einsetzen oder noch schlimmer gleich ein Passwort für alles benutzen. Die Gefahr, die damit einhergeht, ist ganz klar: verschafft sich jemand unerlaubt Zugang zu einem der Konten des Nutzers, stehen ihm Tür und Tor offen zu allen Online-Konten.
Sicherer fährt man nur, wenn man sich starke Passwörter ausdenkt und jedem Online-Konto ein eigenes zuweist.
Wie installiere ich KeePass?
Wie man sich all diese Passwörter merken kann, möchte ich Ihnen im Folgenden aufzeigen. Das Programm meiner Wahl heißt KeePass, es ist OpenSource, Freeware und leicht in der Handhabung. Um KeePass zu nutzen, benötigen Sie ein installiertes .NET Framework 2.0 oder höher.
Zunächst einmal müssen Sie sich KeePass herunterladen:
Legen Sie sich einen Ordner KeePass an und entpacken Sie beide Archive in diesen Ordner – so wie auf nachfolgendem Screenshot sollte es aussehen:
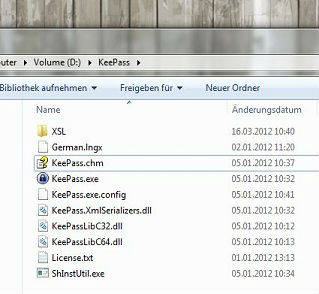
Nach dem Entpacken des Archives von KeePass sind nachfolgende Schritte auszuführen:
- KeePass starten über die KeePass.exe.
- Über den Punkt View->Change Language… die deutsche Sprachdatei auswählen.
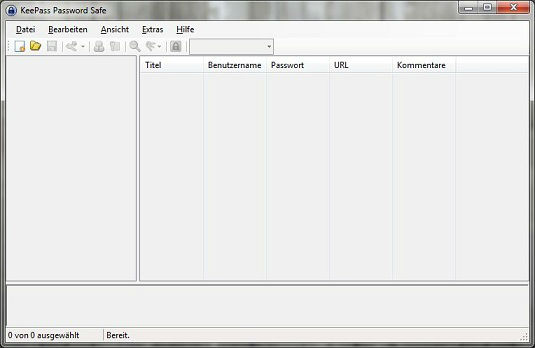
KeePass wird daraufhin automatisch neu gestartet und sollte Sie dann mit der deutschen Oberfläche begrüßen:
Über Datei->Neu… legen Sie eine neue Datenbank-Datei an. Ich lege diese Datei immer im KeePass-Programmordner an, so habe ich alles beisammen und kann es bei Bedarf auf einem USB-Stick mitnehmen.
Anlegen eines Master-Passwortes
Als nächstes geht es darum, die Datenbank mit einem Master-Passwort zu schützen, genauer mit einem sogenannten Mantra, einem Passwort-Satz. Dieser sollte sorgfältig gewählt werden, im Zweifel ist es Ihr einziger Schutz, wenn die Passwort-Datenbank in fremde Hände fällt.
Das Mantra oder generell ein Passwort sollte kein Wort aus einem Wörterbuch sein, egal in welcher Sprache und sei die Sprache noch so exotisch. Zudem sollte man eine Kombination aus Groß- und Kleinbuchstaben, Zahlen und Sonderzeichen wählen. Eine Möglichkeit wäre, sich einen Satz auszudenken, den man sich gut merken kann wie z.B.: Was Fritzchen nicht lernt, lernt Fritz nimmermehr. Man baut Rechtschreibfehler ein und ersetzt einzelne Buchstaben durch Zahlen und Sonderzeichen, so dass am Ende so etwas dabei rauskommt: W4s Fr!7zch3n n!ch7 lärn+, lärn+ Fr!7z n!mmermöhr. Natürlich muss das Mantra nicht so lang sein, dies soll hier nur als Beispiel dienen.
KeePass verschlüsselt mit dem AES-Algorithmus und einer Schlüssellänge von 256 Bit. Um den maximalen Schutz zu nutzen, den diese Methode bietet, müsste das Mantra 32 Zeichen enthalten. Um Ihre Datenbank zusätzlich zu sichern, können Sie eine Schlüsseldatei erzeugen. In diesem Fall bräuchte ein Angreifer zum Öffnen Ihrer Passwort-Datenbank nicht nur das richtige Mantra, sondern auch die dazugehörige Schlüsseldatei, die natürlich nicht gleich im Programmordner von KeePass abgelegt werden sollte.
Wählen Sie ihr Master-Passwort und setzen Sie das Häkchen bei Schlüsseldatei / Provider…
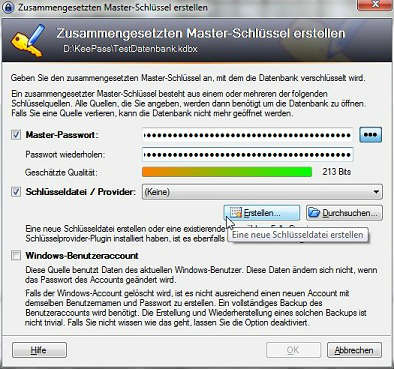
… und klicken Sie auf Erstellen, anschließend den Bildschirmhinweisen folgen bis die Schlüsseldatei erzeugt wird.
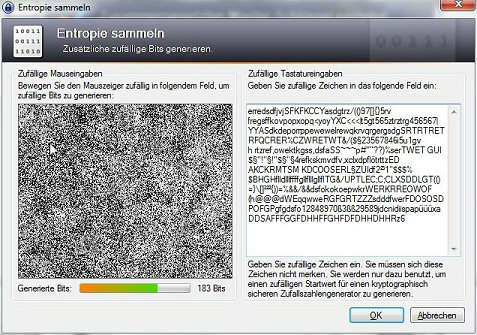
Zum Schluss können Sie mit OK das Erzeugen der Datenbank abschließen und im nächsten Schritt die Vorgaben des Programms ruhig übernehmen und mit OK bestätigen.
Jetzt gelangen Sie wieder in das KeePass Hauptfenster, das dann so aussehen sollte:
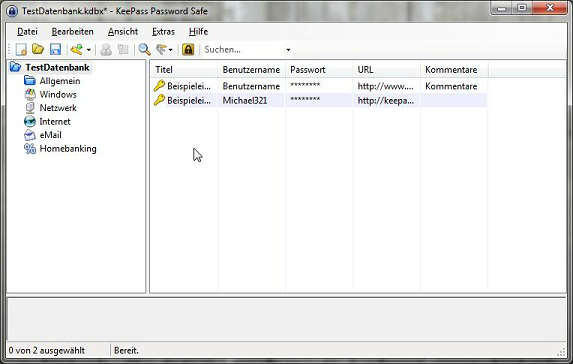
Herzlichen Glückwunsch, Sie haben Ihre Passwort-Datenbank erfolgreich angelegt. Wenn Sie testen wollen, ob alles geklappt hat, einfach das Programm schließen und neu starten. Nun muss das Mantra eingegeben und die Schlüsseldatei eingebunden werden, nur so lässt sich die Datenbank öffnen.
Wie fülle ich die Passwort-Datenbank mit Inhalt?
Als nächstes können Sie die Datenbank mit Ihren Passwörtern füttern, vielleicht eine gute Gelegenheit, für bestehende Accounts neue Passwörter zu generieren.
Wählen Sie in der linken Spalte eine Kategorie und anschließend Bearbeiten->Eintrag hinzufügen… , um einen neuen Eintrag zu erstellen. Im folgenden Dialog füllen Sie die Felder aus. Wichtig ist, dass der Benutzername dem Login-Namen entspricht und unter URL die Adresse zu der Anmeldeseite gesetzt wird.
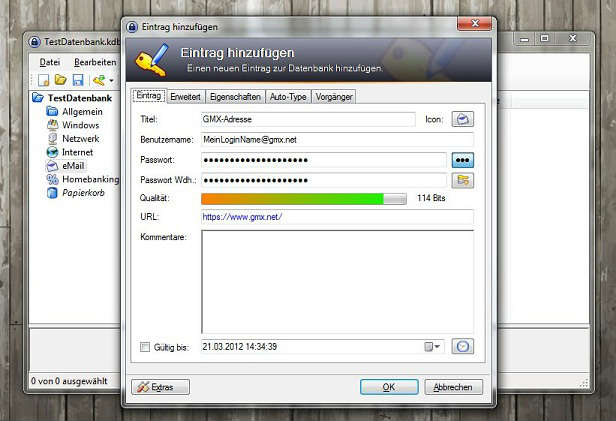
Hat man nun einen Eintrag erstellt und möchte sich beim gewünschten Dienst anmelden, ruft man das Programm auf und wählt den entsprechenden Eintrag. In der unteren Spalte wird die URL angezeigt, mit einem Klick auf den Link öffnet sich Ihr Standardbrowser mit der jeweiligen Website und das Programm KeePass fällt in den Hintergrund. Auf der Website müssen Sie jetzt einmal in das Login-Feld klicken, damit KeePass einen „Anhaltspunkt hat“.
Nun holen Sie KeePass wieder in den Vordergrund und führen einen Rechtsklick auf den Eintrag aus. Aus dem Kontextmenü wählen Sie Auto-Type ausführen.
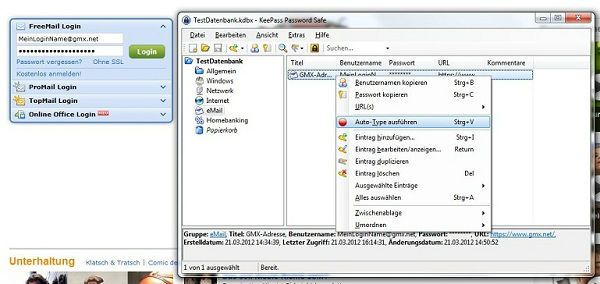
KeePass trägt automatisch die Login-Informationen ein und bestätigt die Eingabe mit ENTER, so dass der Login erfolgt.
Auf diese Weise kann man sich für alle Dienste, die man nutzt, unterschiedliche und sehr komplexe Passwörter leisten und diese auch in regelmäßigen Abständen ändern, ohne sie sich merken zu müssen… bis auf das Master-Passwort natürlich. Zudem hat man die Passwörter in einer zentralen Datenbank – sehr hilfreich, wenn man mit unterschiedlichen Browsern oder Programmen arbeitet, denn KeePass spielt auf diese Weise mit unterschiedlichen Programmen zusammen.
Viel Spaß beim Ausprobieren!