Eine Frau kam eines Tages zu Gandhi und sagte: „Gandhi, bitte sage meinem Sohn, er soll keinen Zucker mehr essen!“ – Gandhi sah die Frau und ihren kleinen Sohn kurz an und meinte dann: „Komm in 2 Wochen wieder“. Die Frau war enttäuscht, denn die Reise war lang und sehr hart gewesen. Diese in 2 Wochen noch einmal anzutreten würde sie sehr viel Kraft und Geld kosten. Aber sie tat es.
Nachdem zwei Wochen vergangen waren stand sie wieder vor Gandhi. Der beugte sich zum kleinen Sohn herunter und sagte: „Junge, iss keinen Zucker mehr.“
Die Frau wurde böse: „DAFÜR sollte ich nun die gleiche Reise nach zwei Wochen noch einmal machen? Warum konntest Du das nicht schon beim letzten Mal sagen?“ Und Gandhi sagte: „Erst musste ich doch selber aufhören Zucker zu essen.“
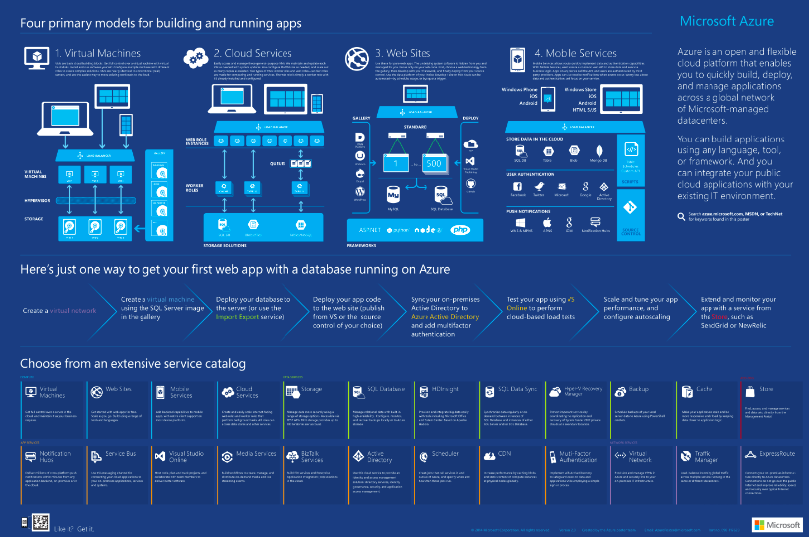
Was hat Gandhi mit automatisch personalisierten Webseiten zu tun?
Ein ganz, ganz wichtiger Punkt um das Potenzial von personalisierten Webseiten voll auszuschöpfen ist es, dass Sie sich in Ihre Besucher hineinversetzen und mit deren Augen sehen. So wie Gandhi sich zunächst selber das Zuckeressen abgewöhnen musste, um darüber mit dem kleinen Jungen zu sprechen.
Was sie in diesem recht langen Artikel, der die schriftliche Version eines Vortrags auf der dmexco 2014 ist, noch erfahren werden, habe ich Ihnen hier einmal zusammen gefasst:
- Gleichen Sie Ihr Angebot mit dem Bedarf des Kunden ab
- Sehen Sie das Verhalten des Nutzers vorher
- Planen Sie Klickverläufe
tl;dr: Durchlaufen Sie verschiedene Wege, die Ihre verschiedenen Benutzer durch Ihre Webseiten führen. Testen Sie verschiedene Klickpfade und Konversionsziele. Wird der Bedarf der Besucher gedeckt und die Erwartungen erfüllt? In diesem Artikel finden Sie einige einfache Beispiele und Werkzeuge, wie Sie das Potenzial für Personalisierung in Ihren Webseiten evaluieren und Nutzerverhalten vorhersehen können.
Was hat ein Hamster in der Mikrowelle damit zu tun?
Dazu kommen wir gleich. Lassen Sie mich vorher kurz aufdröseln, was wir mit personalisierten Webseiten, die sich automatisch und nach vorher festgelegten Regeln auf das Nutzerverhalten anpassen, überhaupt erreichen können:
Komplexität verringern
Sagt Ihnen der Begriff Decision Fatigue – bzw. Paradox of Choice etwas? Wissenschaftler gehen davon aus, dass wir mit einem festen Level an „Entscheidungsenergie“ in den Tag starten. Diese Energie nimmt mit jeder Entscheidung, die wir im Laufe des Tages treffen müssen ab. Es fällt uns immer schwerer neue Entscheidungen zu fällen und irgendwann wehren wir uns sogar vollständig dagegen noch weitere Entscheidungen zu machen.

Dazu gab es im Jahr 2000 ein interessantes Experiment – das Marmeladen Experiment. In einem Supermarkt wurden den Kunden an einem Tag 24 Sorten Marmelade angeboten und am nächsten Tag nur 6 Sorten. Das Ergebnis war verblüffend:
- 24 Marmeladen zogen 60% der Kunden zum Stand. Aber: Nur 2% kauften. Die Auswahl war zu komplex.
- 6 Marmeladen zogen nur 40% der Kunden an. Doch 12% der Kunden kauften aufgrund der einfacheren Entscheidungsfindung.
Personalisierte Webseiten können überflüssiges für den Kunden ausblenden, damit Entscheidungen leichter gefällt werden können.
Besucherverhalten steuern
Wenn wir eine Webseite mit einem speziellen Konversionsziel bauen, dann möchten wir dieses Ziel so oft wie möglich erreichen. Nehmen wir das Beispiel aus der u.s. Grafik: Der Benutzer soll sich zu einer kostenlosen 30-Tage-Demo anmelden. Der Nutzer wird zwischen verschiedenen Infoquellen immer wieder hin und her springen. Dabei auch unsere Kanäle verlassen und wieder zurückkehren.
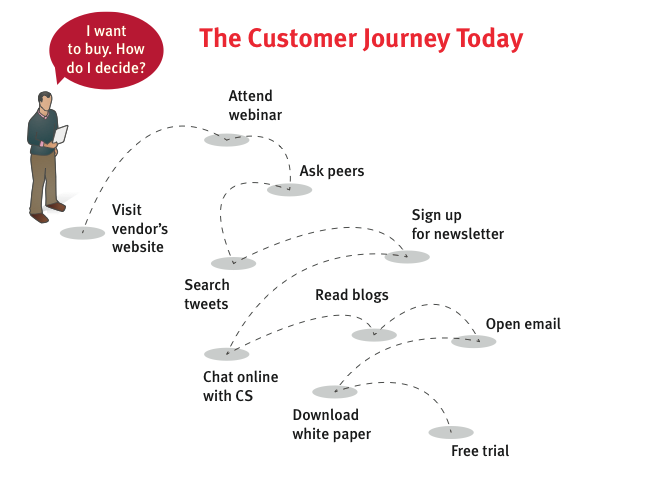
Wir haben nun die Möglichkeit, unsere kostenlose Demo an unterschiedlichen Stellen und Arten immer wieder in den Fokus des Kunden zu bringen. Mit Anmeldekästen, Head-Bannern, kurzen Testimonials usw. bis der Besucher sich anmeldet
Ebenso können wir festlegen ab wann wir den Besucher nicht mehr oder nur noch weniger „nerven“ um eine Übersättigung zu vermeiden.

Wenn der Kunde schlussendlich unser Konversions-Ziel erfüllt hat, stellen wir die Erinnerungen daran ganz ab.
Wir erreichen so weniger komplexe Webseiten, die unsere Kunden einfacher Entscheidungen treffen lassen.
Wechselnde Geräte und Kanäle sind ein weiterer Anwendungsfall. Je nach erkanntem Gerät können andere Produkte, Inhalte oder Daten angezeigt werden. Nutzt jemand die Webseite der Deutschen Bahn bsw. mit dem Smartphone sind Unternehmensbeschreibungen vermutlich irrelevant – umso wichtiger dafür die aktuellen Fahrpläne. Ebenso können Textbausteine für große Bildschirme länger und umfangreicher sein, wobei dem Nutzer auf dem Smartphone-Display Übersicht und Muße zum Lesen fehlen.
Individuelles Storytelling
Diesen Punkt sehen wir uns gleich noch genauer an. Durch die vorab fest gelegten Klickpfade in einer automatisch personalisierbaren Webseite, lassen sich ganze Geschichten erzählen, drehbuchartig orchestriert. Mehr noch: Wir können unsere Nutzer quasi wie in einem Adventure-Computerspiel verschiedene Wege nehmen lassen, bei denen sich die Webseite an die individuellen Entscheidungen des Besuchers anpasst.
Das neue SEO?
Vermutlich ist es nicht zu weit aus dem Fenster gelehnt, wenn ich sage: Automatische Personalisierung könnte das neue SEO werden. Die Komplexität in den Einflussfaktoren ist vergleichbar hoch, die Auswirkungen vergleichbar gut und messbar.
Mit zwei wesentlichen Unterschieden:
- Im Bereich der SEO sind wir von den Vermutungen und Erkenntnissen abhängig, die wir über die Black-Box Suchmaschine erhalten
- Bei der Personalisierung spielt sich der Großteil unserer Anpassungsmöglichkeiten auf unseren eigenen Seiten ohne Einflüsse von außen ab
Wonach lässt sich personalisieren?
Die Faktoren sind schon heute irrsinnig komplex. Bereits in der Einzelbetrachtung. Hinzu kommen natürlich noch unendlich viele Möglichkeiten Einzelbedingungen miteinander zu kombinieren.
- Handelt es sich bei einem Besucher um einen neuen Besucher oder um einen Wiederkehrenden? Ist der Benutzer angemeldet oder anonym? Habe ich CRM-Daten verknüpft?
- Kommt der Klick aus meinem Newsletter? Dann zeige ich die dort geteaserten Angebote an und blende das Anmeldefenster für den Newsletter aus
- IP-Adresse / Geo-Position können Maßgabe sein um landestypische Inhalte anzuzeigen oder auszublenden
- Wetter am Ort des Besuchers: Verkaufe ich Skier und Surfbretter und am Standort meines Nutzers schneit es seit einem Tag sind eventuell Skier interessanter
- Facebook-Fan JA/NEIN? Im Falle von NEIN zeigen wir unser „Werde Fan“-Banner an
- Endgerät entscheidet darüber ob umfangreichere Texte angezeigt werden. Hochpreisige oder preiswerte Endgeräte können über das angezeigte Angebot entscheiden
Zwei Beispiele für automatische Personalisierung
Seitenbereiche nach Klickverhalten anpassen
In diesem Sitecore Beispiel wird dem Benutzer zunächst eine Webseite mit typischen Badeurlaub-Szenarien angezeigt:
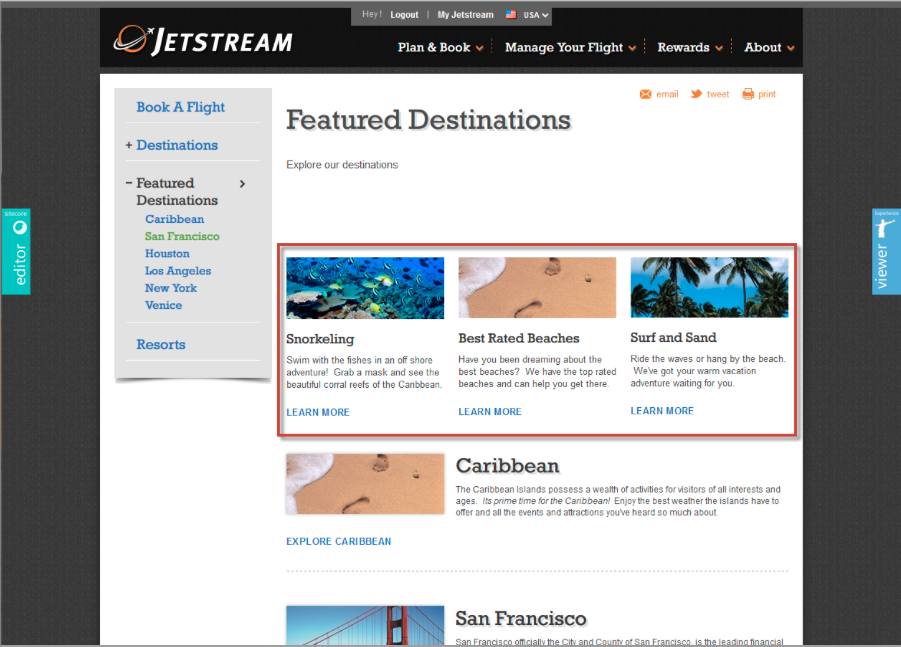
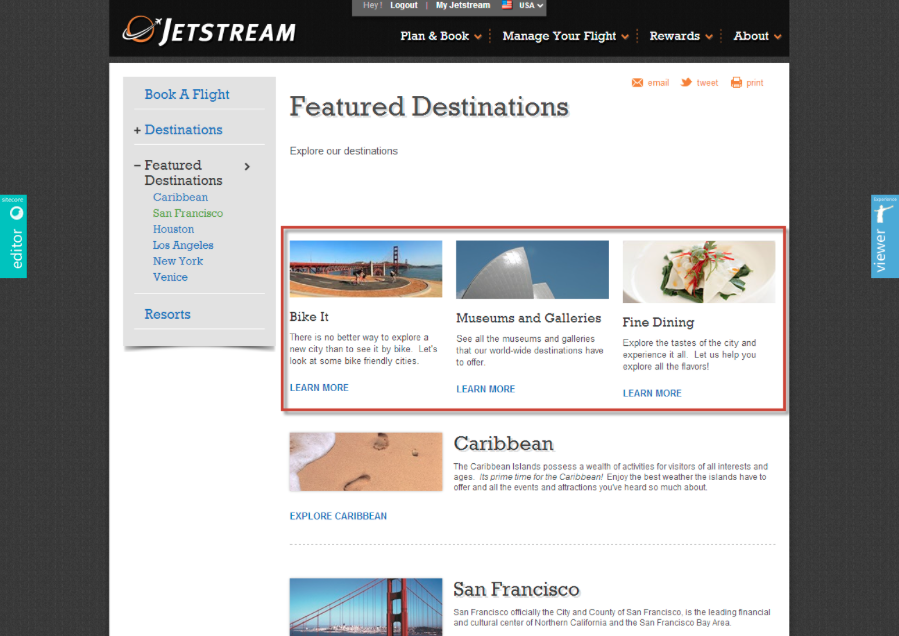
Unser Beispielnutzer klickt nun aber nicht auf den Strand oder die Palmen, sondern interessiert sich für San Francisco. Wir haben vorher festgelegt, dass in diesem Fall ein anderer Klickpfad zur Verfügung gestellt wird und sich die 3 Themen-Angebote oben entsprechend darauf einstellen.
Die drei Kurzteaser wechseln vom Thema Strandurlaub zum Thema Städtereisen und stellen sich damit auf das vermeintliche Interessengebiet des Nutzers ein. (Auch um dieses Verhalten wieder rückgängig zu machen lassen sich Regeln erstellen):
Inhalte automatisch nach Benutzer-Standort anpassen
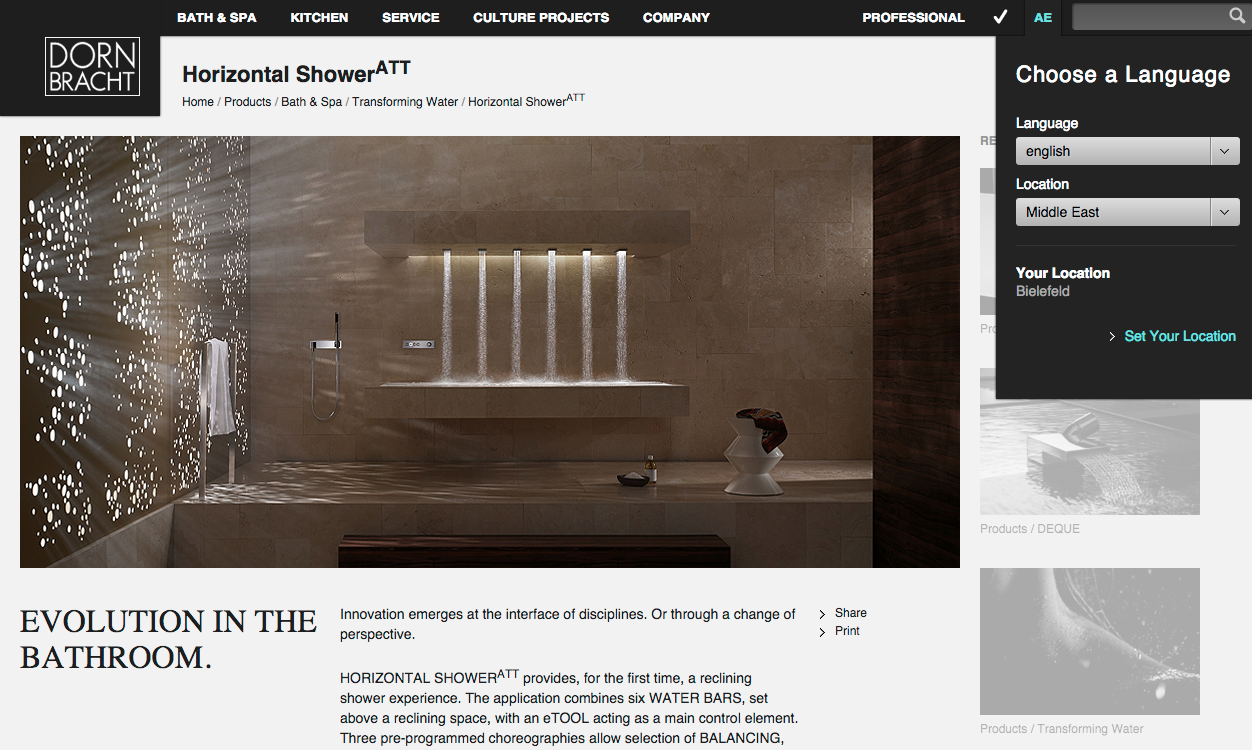
Dieses Beispiel stammt aus einem unserer eigenen Sitecore-Projekte für unseren Kunden Dornbracht. Dornbracht ist Premium-Hersteller u.a. für luxuriöse Badausstattungen und hat in diesem Zusammenhang eine Liegedusche im Portfolio, die Horizontal Shower. Dieses Produkt wird mit einer sehr stimmungsvollen Photographie auf der Webseite vorgestellt.
Inklusive einer unbekleideten Person, die gerade die Liege-Dusche verwendet:
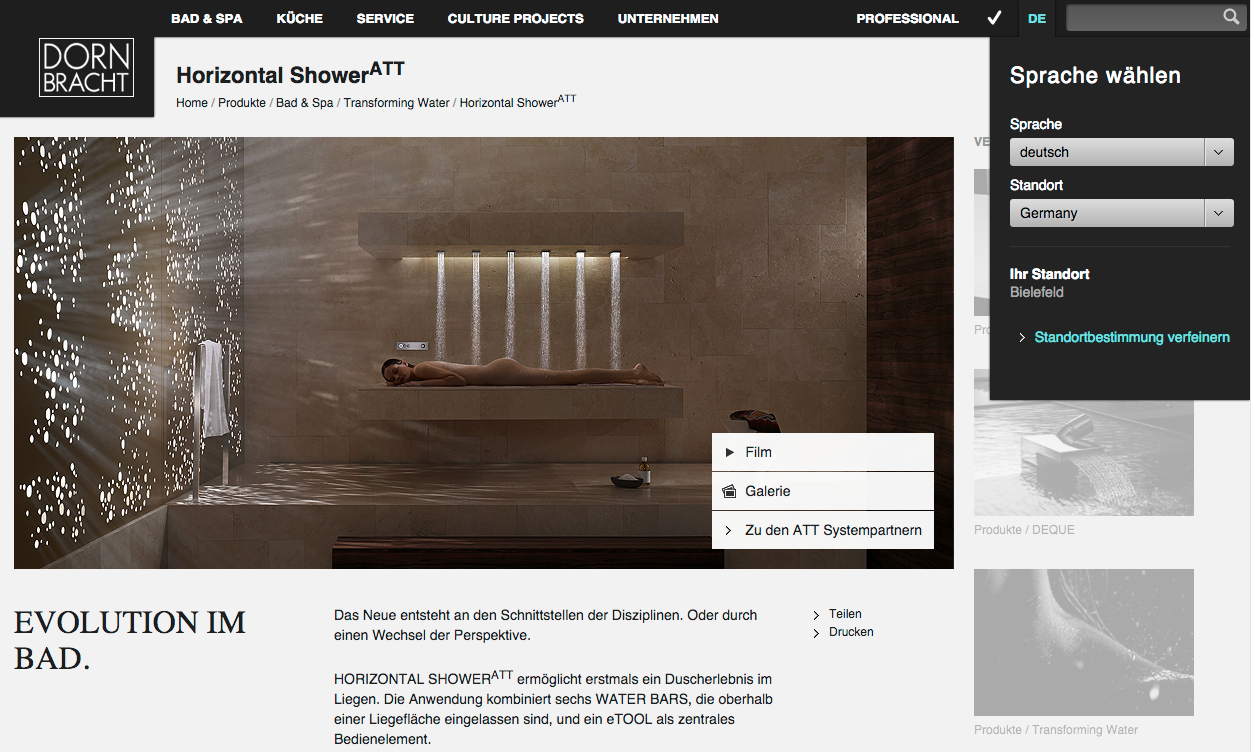
Nun ist es so, dass in manchen Teilen der Welt solche Abbildungen – auch im seriösesten Zusammenhang – als anstößig empfunden werden. Zum Beispiel im arabischen Raum, in dem sich auch ein relevanter Zielgruppenanteil für die Horizontal-Shower befindet. Wir haben also eine Lösung entwickelt, die nach 2 Kriterien entscheidet, wann eine Alternative angezeigt werden soll: Zum einen über die eingestellte Sprache (Englisch im arabischen Sprachraum) und die IP-Adresse.
Im Falle einer positiven Identifizierung wird die Webseite also mit folgender Abbildung ausgeliefert:
Vorhersehen des Nutzerverhaltens
Eben habe ich schon einmal den Vergleich zum Thema SEO heran gezogen. Es gibt noch nicht viele Best Practices für umfangreich automatisierte Webseiten. Wir sprechen hier immer noch von einer Zukunftstechnologie – auch wenn die technischen Voraussetzungen bereits realisierbar sind.
Darum möchte ich zwei Beispiele aus dem Umfeld der Suchmaschinenwerbung heranziehen um zu demonstrieren, wie das Leben des Benutzers erleichtert werden kann und was es heißt, Nutzerverhalten vorhersehen zu können.
SEO = maschinenfokussiert – SEA = menschenfokussiert
Natürlich entwickelt sich SEO ständig weiter. Es wird zum einen komplexer und spezieller, zum anderen kommt man um SEO-Maßnahmen heutzutage nicht mehr herum. Mit Ausnahme vielleicht, wenn man keinen Wettbewerb hat.
Aber: SEO bezieht sich in den allermeisten Fällen auf den Umgang mit Rechnern, Suchmaschinen, Algorithmen. Deswegen wird das Thema Content Marketing immer wichtiger: Beim Content Marketing steht der Mensch, der Nutzer und Adressat des Contents im Mittelpunkt.
Beim SEA (also dem Suchmaschinen-Advertising) war – wie bei allen Werbeformen – der Mensch schon schon immer der zentrale Punkt. „Der Köder muss dem Fisch schmecken.“
Suchmaschinenwerbung über den Ort
Eine Möglichkeit der Personalisierung ist bsw. der Zielort einer Suche. Im folgenden Beispiel wurde nach Ferrari fahren Hamburg“ gesucht. In den darauf folgenden Suchergebnissen war eine auf Ferrari und Hamburg optimierte Landingpage angezeigt sowie eine auf die Suchbegriffe abgestimmte Google-Ads-Anzeige geschaltet.
Beide (rudimentär) personalisierten Wege führen den Besucher nun auf die entsprechende Webseite beim Anbieter, auf der nur Ferraris (statt Porsche) angezeigt werden, die in Hamburg verfügbar sind (statt auch in München bsw.). Im Dropdown-Menu ist Hamburg als Ort auch bereits vorausgewählt.
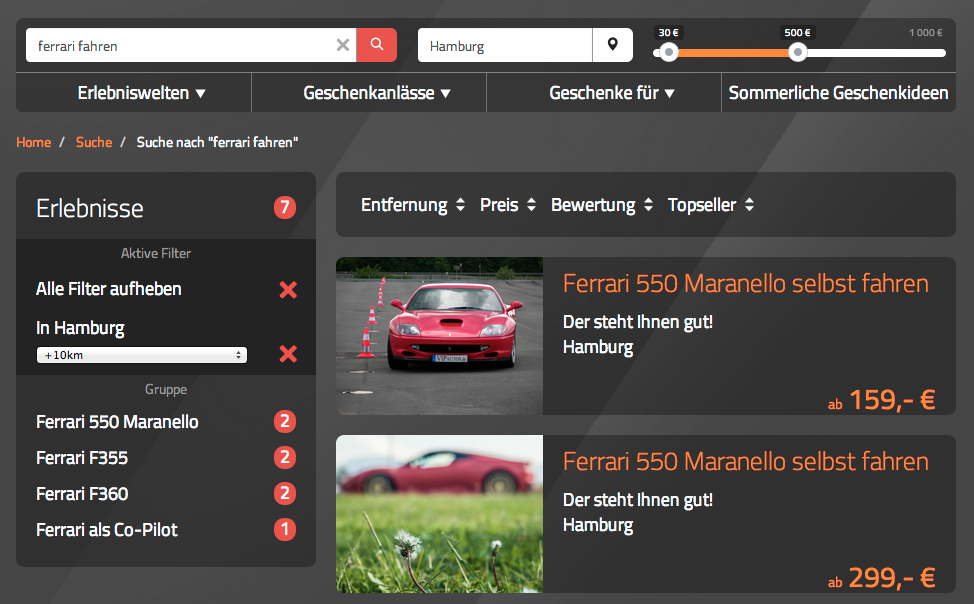
Dem Benutzer wird in diesem Fall vor allem zusätzliche Arbeit des Klickens abgenommen.
Königsklasse der Vorhersehung von Nutzerverhalten
Zugegeben, dieses Beispiel war sehr einfach. Ein meisterhaftes Stück in Sachen Nutzerverhalten antizipieren hat Alec Brownstein 2010 mit seinem Google Job Experiment gezeigt:
Alec sagte für sein „Projekt“ das Nutzerverhalten des Ego-Surfing voraus. Seine Zielgruppe bestand dabei nur aus 5 Personen: Er legte Google-Ad-Anzeigen auf die Namen der CEOs der 5 Top-Werbegenturen an. Wenn diese 5 Werbeagenturchefs nun sich selber googleten, wurde die Anzeige angezeigt (und wer klickt denn bitte schön nicht auf eine Anzeige, die den eigenen Namen enthält?) und führte auf Alex Brownsteins Bewerbung um einen Job in einer der Agenturen.
Bei 4 der 5 CEOs bekam Alex ein Vorstellungsgespräch. Daraus entstanden 2 Jobangebote. Eines davon nahm Alec an. Keine schlechte Konversion oder? 😉
Der Kostenaufwand betrug 6 Dollar.
Der Hamster ist ein historisches Meisterstück des Vorhersehens von Nutzerverhalten
Hervor gebracht hat dieses Meisterstück Ron Gilbert im Jahr 1987. Ron ist der Erfinder des Computerspiels Maniac Mansion. Und damit auch (Mit)-Erfinder des Genres Point-And-Click-Adventure. Die älteren unter uns erinnern sich hoffentlich noch an den guten, alten Commodore C-64 😉

Im Spiel Maniac Mansion musste man sich seinen Weg mit verschiedenen Spielfiguren durch ein verrücktes Spukhaus bahnen, das zudem von verrückten Aliens bewohnt wurde. Ziel des Spiels war es die Freundin der Hauptfigur aus den Händen eines verrückten Wissenschaftlers zu befreien (haben wir ja alle schonmal erlebt, oder?).
Ron Gilbert hat letztens seinen alten Lagerraum aufgeräumt und dabei mit den Maniac Mansion Design Notes historische Relikte der Computerspielgeschichte wieder entdeckt, die uns heute durchaus als Vorlage und Best-Practices für die automatische Personalisierung dienen können.
So hat er bsw. die Original-Zeichnungen und Designdokumente veröffentlicht. So schön diese anzusehen sind, ist für uns aber wichtiger, wie vor über 25 Jahren die Planung des Spielablaufs von statten ging. Eines der Dokumente zeigt zum Beispiel wie die einzelnen Räume des Hause (heute auch Webseiten) miteinander verbunden sind und welche Figuren dort auf den Spieler (heute Inhalte) warten:

Je nach Sympathie und Handlungen des Spielers reagierten die Persönlichkeiten in den Räumen unterschiedlich. Zu den reinen Räumen, Inhalten und Interaktionsmöglichkeiten kamen noch Emotions-Bedingungen hinzu:
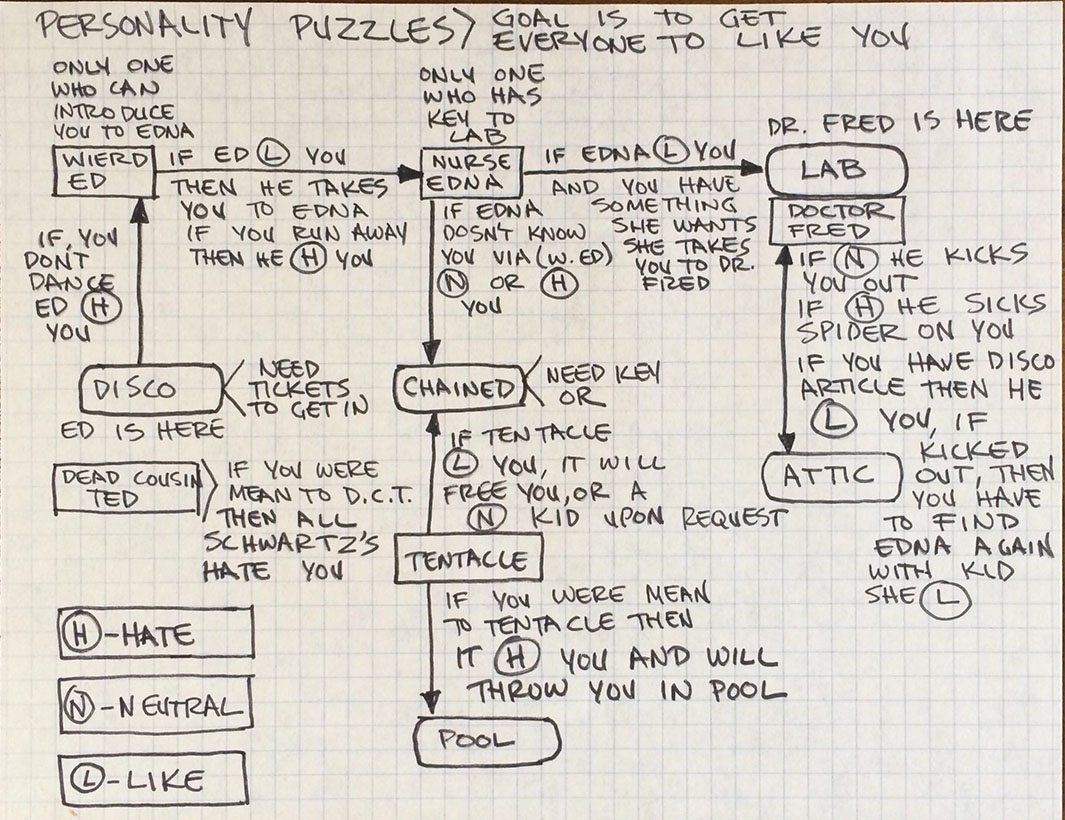
Schließlich wurden im Puzzle Dependency Charts die Bedingungen festgelegt, wann in welchen Räumen was passieren muss um die nächsten Schritte zu ermöglichen. In diesem Fall hier musste in einem Raum ein Schlüssel gefunden werden und in einem weiteren eine Kanne mit Öl. Der Schlüssel schloss die Kellertür auf, das Öl aus der Kanne machte die Tür wieder beweglich. So können auch verschiedene Bedingungen auf Webseiten zusammen „geschaltet“ werden, um eine weitere Aktion zu ermöglichen oder Interaktions-Möglichkeit anzuzeigen.
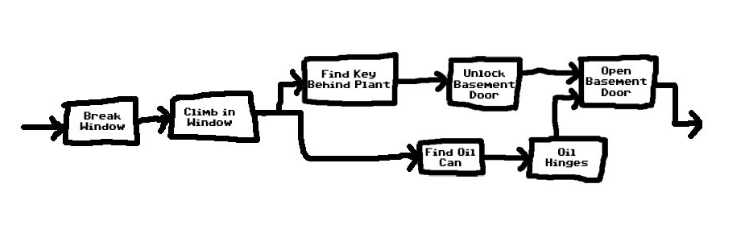
Maniac Mansion ließ den Spieler eine Menge verrückter Dinge tun, die sich nicht unbedingt alle auf den eigentlichen Spielerfolg auswirkten. Dabei hat Ron Gilbert die skurrilsten Handlungen vorhergesehen.
Der arme Hamster
Kommen wir endlich zu unserem Beispiel-Nagetier:

Man beachte das Poster an der Wand: Auf dem Poster neben der Tür des virtuellen Zimmer ist eine sehr vereinfachte Variante des Entscheidungsbaums der im Spiel zum Einsatz kommt abgebildet!
Zwischen diesem Poster und der Tür befindet sich der besagte Hamster in seinem Käfig. Diesen konnte man als Spieler mit dem Klick auf NIMM und dann das Objekt Hamster mitnehmen.
In der Küche des Maniac Mansion angelangt war es dem Spieler möglich, den Hamster in die Mikrowelle zu legen und das Küchengerät einzuschalten. Sehr morbider Humor. Zugegeben. Vermutlich würde sich das heute auch kein Spielehersteller mehr trauen.

Es zeigt aber, wie gut Ron Gilbert damals bereits das Nutzer- bzw. Spielerverhalten vorhersehen konnte. Schließlich hatte die ganze Koch-Aktion des Hamsters überhaupt keinen weiteren Sinn im Spiel.
Was zeigt uns der Hamster für unsere Webseiten?
Mit einem gut und detailliert ausgearbeiteten Entscheidungsbaum lässt sich nicht nur Nutzerverhalten antizipieren, sondern eine Geschichte erzählen, die den Besucher ins Geschehen einbezieht, Bindung aufbaut und Begeisterung erzeugt. Wir können Fälle entdecken, die uns sonst nicht auffallen würden und das Verhalten der Webseite daran anpassen:
Was soll der Besucher im Fall X anderes sehen, als im Fall Y und welches Verhalten führt zu Fall Z?
„Das ist doch alles furchtbar viel Arbeit!“ höre ich Sie jetzt sagen. Und ja, Sie haben Recht. Webseiten zu personalisieren ist zu Anfang ein großer Brocken Arbeit und im folgenden ein stetiger Prozess. Der meiste Teil dieser Arbeit findet dabei im Kopf des Marketings-Teams statt.
Die gute Nachricht ist:
Es gibt einfache Werkzeuge um die geleistete Denkarbeit in die Webseite zu übertragen. Den Sitecore Engagement Plan zum Beispiel:

Das kommt Ihnen nun sicher bekannt vor? Unterscheidet sich vom Prinzip her nicht sonderlich von den Maniac Mansion Design-Dokumenten aus 1987.
Mit Sitecores Rule Editor werden Bedingungen für das Nutzerverhalten auf der Seite erstellt. Das Tool ist genauso leicht zu bedienen, wie der Filter-Assistent von Microsoft Outlook.
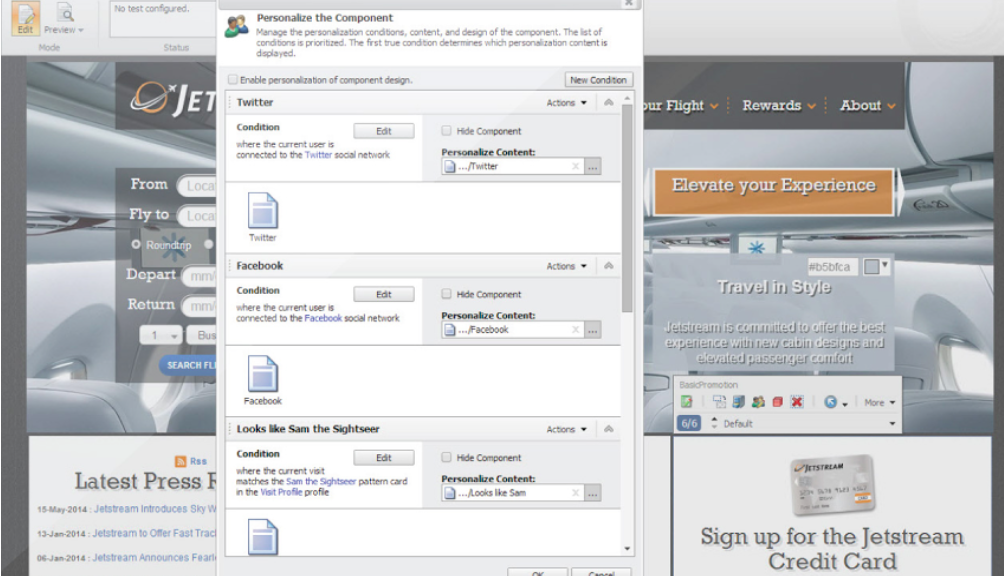
Zukunftsausblick
Es ist sicher nicht allzu vermessen davon auszugehen, dass Content Management Systeme in Zukunft in der Lage sein werden nach vorher festgelegten Algorithmen zu lernen und sich automatisch selbst an das Verhalten der Nutzer anzupassen. Amazon ist hier ja bsw. ein sehr bekannter Vorreiter („Kunden die diesen Artikel gekauft haben, kauften auch…“) Allerdings ist ein Algorithmus im weitesten Sinne und auf seine Grundbestandteile reduziert auch nichts anderes als ein Entscheidungsbaum, den man sich vorher im Kopf überlegt hat.
Unser praktischer Tip zum personalisieren von Webseiten daher:
Machen Sie es wie Gandhi. Versetzen Sie sich gedanklich in Ihre verschiedenen Benutzer und spielen Sie Ihre Webseite durch.
Dokumentieren Sie das Verhalten der Webseite mit einfachsten Mitteln: Zettel & Stift
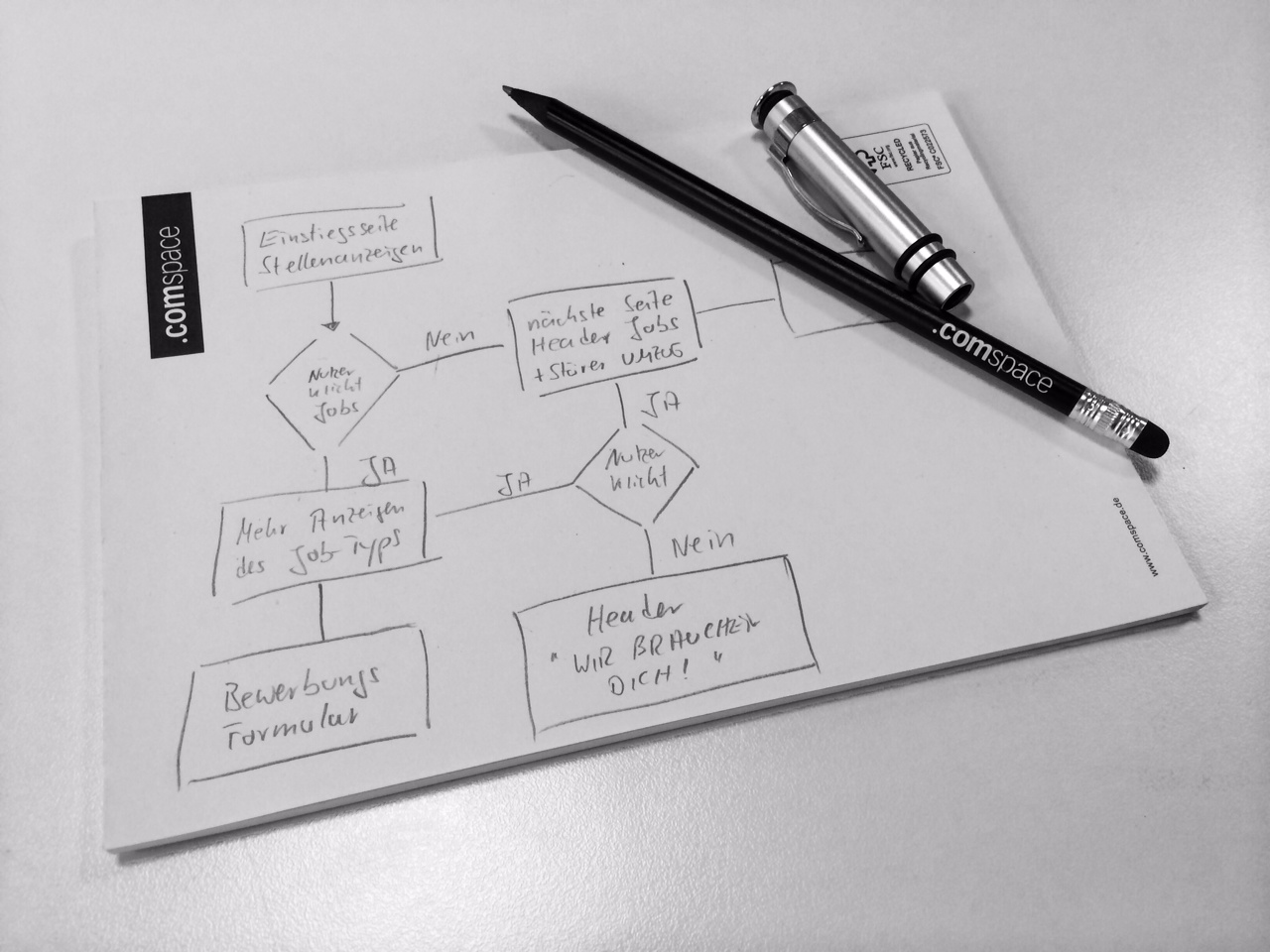
Erstellen Sie so Entscheidungsbäume und Klickpfade, anhand derer Sie erkennen, wo Ihnen eine automatisch personalisierte Webseite einen Wettbewerbsvorteil in Form von mehr Umsatz, Einsparungen von Arbeit und Zeit sowie zufriedeneren Kunden bringen kann.
Ach und noch eine Sache:
Bei der Entwicklung solcher Klickdiagramme entdecken Sie möglicherweise auch unterhaltsame und skurrile Interaktionen wie den Hamster in der Mikrowelle. Solche Easter Eggs haben durchaus das virale Zeug dazu, Ihre Besucher so zu begeistern, dass sie über 25 Jahre später noch an das Erlebnis auf Ihrer Webseite denken 😉 Das einfachste Beispiel ist hier wohl die Google-Sucheingabe „do a barrel roll“ oder falls Sie iPhone-Nutzer sind, stellen Sie Siri einmal die Frage: „Siri, was sagt der Fuchs?“ und danach fragen Sie einfach noch einmal 🙂
Wenn Sie mehr über die Möglichkeiten von automatisch personalisierten Webseiten erfahren möchten, vereinbaren Sie hier ein unverbindliches Beratungsgespräch mit unseren Experten.
Was wurde eigentlich aus dem Hamsterkiller?
Die Auflösung bin ich Ihnen ja noch schuldig. Natürlich war der kleine Handlungsstrang mit dem gekochten Hamster in der Küche noch nicht beendet.
Geht man mit dem gekochten Hamster zurück in das Zimmer, aus dem man das Tierchen entwendete, steht dort Ed, der außerirdische Hamsterbesitzer neben dem leeren Käfig.

Gibt man Ed nun den gekochten Hamster zurück, nimmt das Spiel ein jähes und berechtigtes Ende. Soll niemand sagen, dass Hamstermord nicht bestraft wird!

Übrigens: Ron Gilbert ist einer der wenigen Menschen, der sich einmal (trotz vorheriger und eingehender Warnung dies nicht zu tun) mit Steve Jobs gestritten hat. Diese wunderbare Geschichte gibt es wie viele weitere Einblicke in die wunderbare Welt der Computerspiele drüben auf seinem Blog grumpygamer.com.
Den vollständigen Spielverlauf von Maniac Mansion in einzelnen Screenshots können Sie sich hier anschauen.