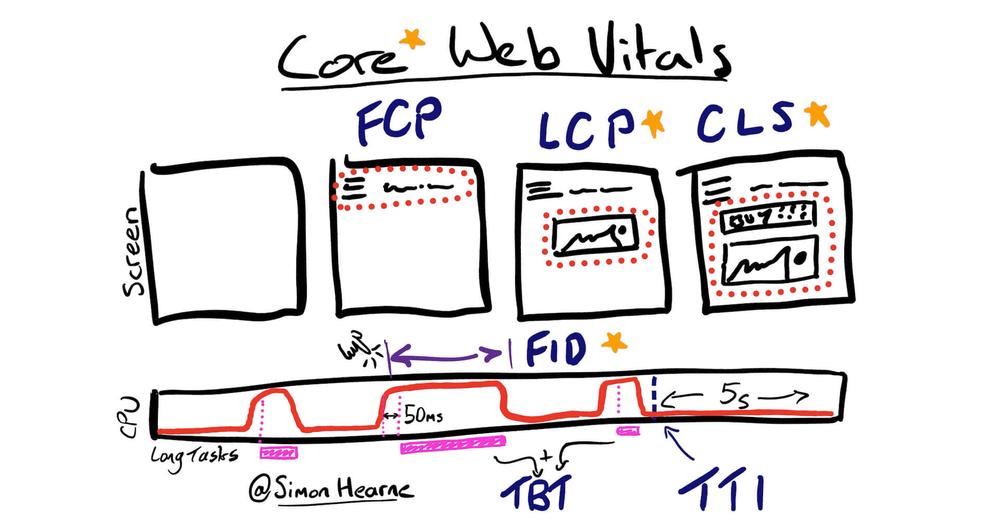
Mit der Ankündigung von zwei Neuerungen in 2021 treibt Google die technische Entwicklung von Websites weiter voran. Ab März wird das Mobile First Indexing für alle Webseiten zum Standard und ab Mai Mitte Juni erhebt Google mit dem Page Experience Update die Nutzererfahrung zum Rankingfaktor.
Bilder komprimieren ist eine wichtige Aufgabe, die Redakteur, Autoren und Blogger jeden Tag übernehmen. Jedes Bild, dass auf einer Webseite einen Platz finden wird, sollte komprimiert werden. In diesem Blogpost versuche ich herauszufinden, welches Bildkomprimierungs-Tool das Beste für meinen Use Case ist.
Das Thema Pagespeed / Website Geschwindigkeit geistert gefühlt schon seit Jahren durch die Internetwelt. Warum sollen Websites schnell sein und was ist eigentlich mit der Website Geschwindigkeit gemeint? Wer definiert, was langsam und vor allem was schnell ist?
Fangen wir erst mal mit den Punkten an, was Website Geschwindigkeit meint und wieso Websites überhaupt schnell sein sollen.
Website Geschwindigkeit (PageSpeed)
Wenn vom PageSpeed bzw. der Website Geschwindigkeit gesprochen wird, ist in erster Linie die Ladezeit einer Website gemeint. Mit der Ladezeit wird die Zeit beschrieben, die benötigt wird, bis eine Website vollständig geladen ist, so dass ein Besucher den Inhalt einer Website sehen kann.
Denn je schneller eine Website geladen wird, desto schneller kann der Besucher die Inhalte lesen und entsprechend innerhalb der Website navigieren. Des Weiteren sorgen schnelle Ladezeiten dafür, dass Besucher eine Website tatsächlich besuchen und nicht aufgrund von langen Ladezeiten den Besuch abbrechen, bevor der eigentliche Inhalt vollständig geladen ist. Ebenfalls eine Frage der Usability.
Übrigens hat der Suchmaschinenbetreiber Google den Begriff „PageSpeed“ geprägt und stellt auch einige interessante Hinweise, Tipps und Tricks zur Optimierung der Website Geschwindigkeit zur Verfügung. Der aber mittlerweile wichtigste Grund für schnelle Ladezeiten ist der, dass der PageSpeed ein Ranking Kriterium für Websites ist und kürzere Ladezeiten das Ranking unterstützen können.
Geschwindigkeit: Was ist langsam und was ist schnell?
Den meisten wird Ladezeit ein Begriff sein, auch dass es Optimierungspotentiale wie zum Beispiel die Verringerung von Bildgrößen und das Minimieren von internen und externen Abfragen gibt.
Aber die Frage, die sich eigentlich stellt ist, woher weiß ein Webseitenbetreiber, ob eine Website langsam oder schnell ist? Zum einen gibt es eine Vielzahl an Diensten mit denen die Geschwindigkeit einer Website gemessen werden kann und zum anderen stellt der Suchmaschinenbetreiber Google in seinen Google WebmasterTools eine Leistungsübersicht für die Website zur Verfügung.
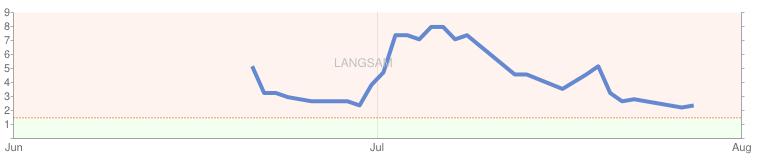
Beispiel Diagramm: Entwicklung des Pagespeeds
Schauen wir uns die obere Grafik etwas näher an, dann erkennen wir dass die Website die zu dieser Grafik gehört, in den vergangenen Monaten seitens Google bzgl. der Ladezeit überprüft wurde. Die optimale Ladezeit für eine Website liegt laut Google im Bereich von max. 1.5 Sek. – mit aktuell rund 2.3 Sek. Ladezeit steht die obere Website nicht schlecht dar, aber auch nicht wirklich gut. Das bedeutet, es muss nach Optimierungspotentialen Ausschau gehalten und diese umgesetzt werden.
Das Ziel sollte also sein, langfristig zu erreichen, dass die Ladezeit bei unter 1.5 Sek. liegt. Das einzige Manko an der Übersicht in den Google WebmasterTools ist, dass leider keine genaue Angabe darüber existiert, von wo aus die Website abgerufen wird. Logischerweise erhöht sich die Ladezeit, wenn Website A aus den USA und nicht aus dem europäischen Raum abgerufen wird. Die Datenwege sind entsprechend länger.
Geeignete Tools zur Überprüfung des PageSpeeds
Vorweg sei gesagt, dass die meisten Tools eine Vielzahl von Optimierungspotentialen einschließlich detaillierter Erklärungen aufzeigen, die anschließend direkt in die ToDo-Listen übernommen werden können.
Zu einer Webseite gehört auch die regelmäßige Prüfung, ob diese entsprechend den eigenen Vorstellungen funktioniert und seitens der Besucher sowie den Suchmaschinen-Crawlern abgerufen werden kann.
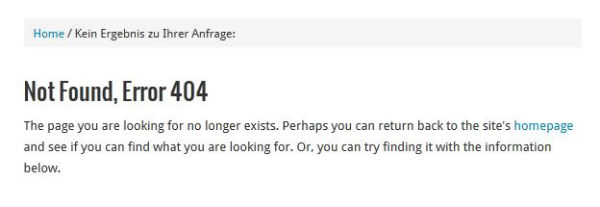
Besonders wichtig ist dabei zum Beispiel das Prüfen von internen und externen Links und eben das Vermeiden von 404-Fehlerseiten. Denn sowohl für den Besucher wie auch für Suchmaschinen ist es nicht von Vorteil, wenn Inhalte aufgrund fehlerhafter Links nicht erreichbar sind – der Besucher erhält somit den gewünschten Mehrwert nicht und verlässt die Webseite mit dem Gedanken „die Webseite ist unbrauchbar und funktioniert nicht“ und Suchmaschinen können den brandaktuellen und wichtigen Inhalt nicht in die Suchergebnisse aufnehmen, da dieser nicht verfügbar ist und mit hoher Wahrscheinlichkeit einen 404-Fehler liefert. Ebenfalls sollte auch eine hohe Anzahl von 404-Fehlern vermieden werden – dazu ist es einfach wichtig, regelmäßig, z.B. einmal im Monat, die Verlinkungen durch Programme wie Xenu’s Link Sleuth und durch Inanspruchnahme der Google Webmaster Tools zu prüfen und eventuelle Fehler zu begradigen.
Häufig verstecken sich aber auch Fehler im Detail – wie bereits im vorigen Artikel zum Thema „Richtlinien zur Gestaltung von Webinhalten: Aufbau des Inhalts (Teil 1)“ angesprochen sollten Webseiten einer regelmäßigen Prüfung auf Syntax-Fehler unterzogen werden. Dies sollte durch einen sogenannten W3-Validator geschehen – neben der rein technischen Überprüfungen des HTML / CSS Quellcodes ist eine Überprüfung der verschiedenen Webbrowser einschließlich ihrer unterschiedlichen Versionen eine durchaus sinnvolle Maßnahme. Beispielsweise kann eine Webseite im Internet Explorer 6 anders aussehen als im Internet Explorer 9, denn es gibt Unterschiede zwischen den einzelnen Browseranbietern wie z.B. Mozilla Firefox, Microsoft Internet Explorer oder den Safari von Apple. Der Grund für die unterschiedlichen Darstellungen von Webseiten in verschiedenen Browsern liegt in der Interpretation von HTML/CSS Elementen. Beispielsweise kann es sein, dass ein Mozilla Firefox ein HTML-Element anders interpretiert als der Internet Explorer. Eine gute Übersicht zu den Unterschieden einzelner HTML-Elemente und CSS-Elemente sind auf der Webseite css4you.de zu finden. Des Weiteren kann die Darstellung einer Webseite in verschiedenen Browsern sehr einfach auf Browsershots.org überprüft werden.
Ein weiteres Kriterium, dass durchaus im Auge behalten werden sollte, ist die Ladezeit einer Webseite – es ist bereits länger bekannt, dass die Ladezeit ein Kriterium für das Ranking einer Webseite ist und auch Google hat den Pagespeed bereits in die Google Webmaster Tools aufgenommen. In den Google Webmaster Richtlinien sagt Google selbst zum Pagespeed, dass schnelle Webseiten die Zufriedenheit der Nutzer und die Gesamtqualität des Internets steigern. Lange Ladezeiten sorgen allgemein dafür, dass Besucher schnell abspringen und selbst in der heutigen Zeit gibt es noch die einen oder anderen Internetnutzer, die aufgrund von ländlichen Begebenheiten nicht in der Lage sind, mit DSL-Geschwindigkeit das Internet zu erleben. Auch hier sollte eine regelmäßige Überprüfung der Webseiten-Geschwindigkeit erfolgen. Dazu eignen sich nachfolgende Tools aus dem Hause vn Google.
Unsere Empfehlung ist das Tool von GTMetrix, da dieses eine sehr angenehme und v.a. verständliche und strukturierte Übersicht bietet. Des Weiteren lassen sich schnell Optimierungspotentiale, wie z.B. die Optimierung von Bildgrößen/Dateigrößen, erkennen.
Weitere Artikel zum Thema Google Webmaster Richtlinien
Auch bei den technischen Richtlinien gibt es einige Vorgaben, die in den Google Webmaster Richtlinien Erwähnung finden und nebst den Webmasterrichtlinien zur Gestaltung von Webinhalten als Unterstützung für die Optimierung der eigenen Webseite dienen.
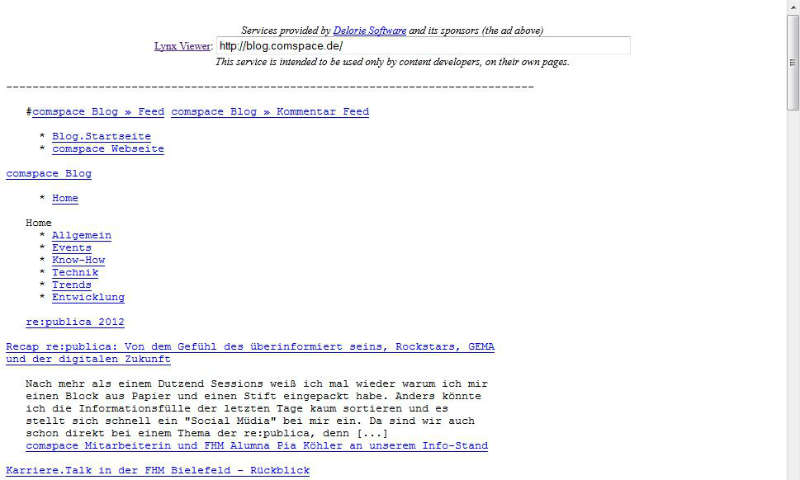
Überprüfung der Webseite durch einen textbasierten Browser
Lynx-Abbild von Comspace Blog
In erster Linie darf man sich einen Crawler, der Webseiten erfasst und ausliest, wie einen einfachen Textbrowser vorstellen. Gängige Browser wie der Mozilla Firefox, Google Chrome, Apple Safari oder den bekannten Microsoft Internet Explorer sind in der heutigen Zeit in der Lage, Webseiten in voller Pracht anzuzeigen, das heißt vorhandene Grafiken oder auch Flash-Videos werden nach dem Wunsch der Seitenbetreiber dargestellt. Textbrowser, wie beispielsweise Lynx, stellen Webseiten – wie der Name es schon sagt – in reiner Textform dar. Bilder und andere Elemente wie zum Beispiel Videos werden in einem Textbrowser nicht angezeigt.
Des Weiteren sind in einem Textbrowser diverse Funktionen wie JavaScripte, Cookies und Session-IDs nicht nutzbar bzw. können für Probleme sorgen. Ähnlich agieren auch Webcrawler – auch wenn diese mittlerweile weiterentwickelt wurden und relativ leistungsfähig sind, kann ein Webcrawler mit den oben genannten Elementen auf einer Webseite Probleme haben.
Pauschal lassen sich natürlich nicht alle Elemente auf einer Webseite entfernen – ein Onlineshop ohne entsprechende Bilder oder Produktvideos wäre im Jahre 2012 undenkbar. Dem entsprechend ist hier die technische Aufgabe des Webseitenbetreibers dafür zu sorgen, dass die Crawler der Suchmaschinen es möglichst einfach haben, die Inhalte der Webseite zu crawlen.
Zum einen hat der Webseitenbetreiber die Möglichkeit, seine Internetpublikation mithilfe des eben erwähnen Lynx Textbrowsers zu prüfen – zum anderen bieten aber auch die Google Webmaster Tools die Möglichkeit, eine Webseite durch einen Crawler abzurufen und sich das Ergebnis ausgeben zu lassen.
Exkurs: Cloaking und ungeeignete Techniken
Die obigen Gründe und die anfänglichen Schwierigkeiten hatten zur Folge, dass in der Anfangszeit des kommerziellen World Wide Webs diverse Techniken entwickelt wurden, die dafür sorgten, dass Suchmaschinen wie Google beim Besuch einer Webseite komplett andere Inhalte angezeigt wurden als dem Endverbraucher. Die Technik war dabei relativ einfach: Wenn eine Webseite besucht wurde, wurde zu Beginn abgefragt, ob es sich um einen realen Besucher handelt oder ob hier ein Suchmaschinencrawler unterwegs ist – sobald ein Suchmaschinencrawler erkannt wurde, zeigte man diesem einfach die Webseite in einer anderen Form.
Mittlerweile sind solche Techniken seitens der Suchmaschinen nicht sonderlich gern gesehen und können im Ranking zu Abwertungen führen. Diese Technik machten sich natürlich auch andere Personen zu Nutze und verschleierten somit Inhalte, die nicht zwangsläufig in Suchergebnissen auftauchen sollten bzw. die seitens der Suchmaschine erst gar nicht erkannt werden sollten.
Suchmaschinen die Aktualität der Seite präsentieren
Im ersten Teil „Richtlinien zur Gestaltung von Webinhalten: Aufbau des Inhalts“ wurde bereits angesprochen, dass die Qualität des Inhalts eine wichtige Rolle für ein positives Ranking innerhalb der Suchmaschinen spielt. Nebst der Qualität des Inhalts ist auch die Aktualität, sprich wie oft neue Inhalte publiziert oder ältere Inhalte aktualisiert werden, relevant und sorgt natürlich auch dafür, dass Crawler eine Webseite regelmäßiger besuchen könnten. Wenn ein Crawler bemerkt, dass eine Webseite regelmäßig bzw. täglich neue Inhalte veröffentlicht, wird auch der Crawling-Rhythmus automatisch angepasst.
Um dem Crawler relativ schnell mitzuteilen, ob neue Inhalte verfügbar sind, empfehlen die Google Webmaster Richtlinien die Verwendung des http-Headers “If-Modifies-Since“. Anhand dieser Funktion teilt der Webserver dem Crawler mit, wann neue Inhalte auf der Internetseite veröffentlicht wurden – natürlich kann dies auch anhand der Webseite an sich geschehen, wenn beispielsweise eine Zeitangabe für die Erstellung des Artikels existiert. Im Gegensatz zu der Zeitangabe auf der Webseite besitzt die Lösung des http-Headers den Vorteil, dass Bandbreite eingespart werden kann.
Inhalte vor dem Crawler schützen
Suchmaschinen ist das Durchsuchen/Indexieren der Webinhalte erlaubt
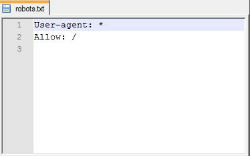
Selbst in der heutigen Zeit sind für viele Webseiten-Betreiber Begriffe wie Robots.txt und Meta-Robot ein Fremdwort. Doch dabei ist es nicht verkehrt, dem Suchmaschinen-Crawler mithilfe einer Robots.txt mitzuteilen, welche Verzeichnisse durchsucht werden sollen und welche eben nicht durchsucht werden sollen – schließlich muss nicht jeder Inhalt oder gar jedes Bild im Index der Suchmaschinen dargestellt werden.
Besonders wichtig ist dabei, dass der Webseitenbetreiber selbst die vorgenommenen Anweisungen in der eigenen Robots.txt kontrolliert, da es auch passieren kann, dass Suchmaschinen-Crawler komplett ausgeschlossen werden. Als Hilfsmittel für die Kontrolle eigenen sich die Google Webmaster Tools, womit zum einen die Robots.txt geprüft werden kann und zum anderen die Seite durch einen Crawler abgerufen werden kann. An den Resultaten lässt sich erkennen, wie der Google-Bot die Webseite sieht und natürlich welche Inhalte der Bot abgreifen kann und welche nicht.
Neben der Erstellung einer Robots.txt gibt es auch die Möglichkeit für einzelne HTML-Seiten mittels dem Meta-Tag „<meta name=“robots“ content=“index,follow“ />“ bestimmte Einstellungen vorzunehmen, die einem Suchmaschinen-Crawler mitteilen, ob die Inhalte indexiert werden dürfen („index“) oder nicht indexiert werden dürfen („noindex“). Zudem kann angegeben werden, ob den Links auf der einzelnen Seite gefolgt („follow“) oder nicht gefolgt („nofollow“) werden sollen.
Die Webseite auf Herz und Nieren testen (Teil 2.1)