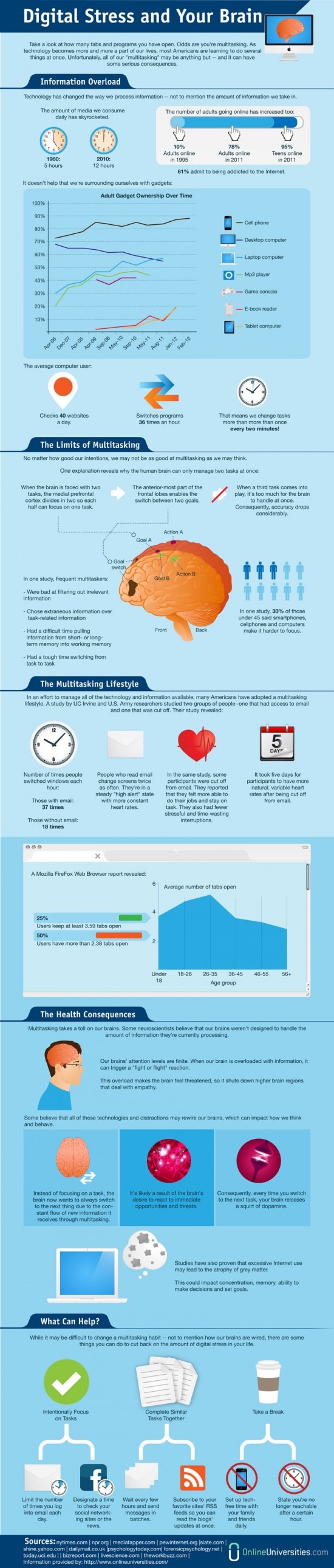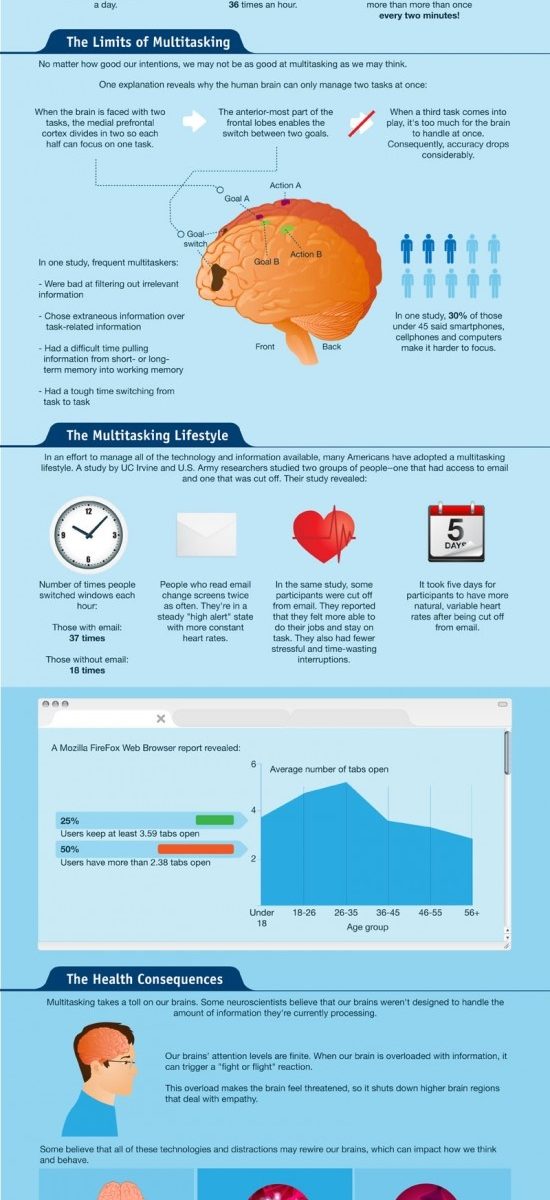
Wussten Sie, dass viele Bildschirmarbeiter in einer Stunde 36 Mal das Programm wechseln? Und dass sie ohne E-Mail Zugang am Arbeitsplatz nur halb so oft switchen? Wie entsteht digitaler Stress und wie wirkt er sich auf die Produktivität aus?
Das Blog Karrierebibel, auf dem ich die untenstehende Grafik entdeckt habe schreibt zum Thema digitaler Stress:
Ich bin sicher, würde Einstein heute noch leben und genauso simsen, mailen, twittern und facebooken, wie wir es tun – er säße vermutlich noch immer in seinem Berner Patentamtsbüro und hätte nie die Zeit und Muße gefunden, seine Relativitätstheorie zu entwickeln.
Da könnte was dran sein. Die Menge an Medien, die wir täglich konsumieren, ist von 5 Stunden in 1960 auf 12 Stunden in 2010 (in den USA) gestiegen. Zu Einsteins aktiven Zeiten dürfte das wohl noch etwas weniger gewesen sein.
Klar, es gibt Berufe, in denen gehört es einfach zur Aufgabe, dauererreichbar zu sein. Der Projektmanager ist ein klassisches Beispiel:
Unsere Projektmanager hier bei comspace sind bspw. bestrebt, unseren Kunden innerhalb eines vorgegebenen Zeitraums auf E-Mails zu antworten. Das heißt nicht, dass jedes Problem innerhalb von X Minuten gelöst werden kann, wenn mehrere Experten in eine Lösungsfindung involviert sind, aber innerhalb der vereinbarten Zeit wird sich um ein Ergebnis gekümmert und Feedback an den Kunden gegeben. Es entsteht ein ständiger Kommunikationskreislauf.
Andere Mitarbeiter wie bspw. Entwickler benötigen häufig zunächst eine bestimmte Zeit, um überhaupt in ihren produktiven „Flow“ zu kommen. Und die Aufgabe oder das Problem, an dem gerade gearbeitet wird, zu erfassen und eine Lösung zu erarbeiten. Hier sind Unterbrechungen oft tödlich für die produktive Arbeit. Die kleinste Ablenkung kann dafür sorgen, dass die über den halben Tag aufgebaute Konzentration auf einen Schlag weg ist. Daher sieht man bei uns auch den einen oder anderen Mitarbeiter unter einem Kopfhörer stecken, um jeden Einfluss von außen auszublenden und sich voll fokussieren zu können.
Diese Art von Problemen haben wir uns als Technologiegesellschaft natürlich selbst geschaffen. Das war die schlechte Nachricht.
Die gute ist: Wir können sie auch wieder lösen bzw. abschaffen.
Mein Aufgabenbereich als Blogger und Social Media Manager liegt genau zwischen den oben beschriebenen Tätigkeitsfeldern: Wenn ich schreibe, brauche ich vollständige Ruhe. Wenn ich an einem Team-Projekt sitze, recherchiere oder an sozialer Vernetzung im Web arbeite, muss ich ständig zwischen verschiedenen Programmen, Zusammenhängen und Tätigkeiten wechseln.
Meine Taktiken, um den Überblick nicht zu verlieren sehen z.B. so aus:
- Handies und Festnetztelefone sind in Konzentrationsphasen lautlos
- E-Mails werden nur zu festgelegten Zeiten oder bei Konzentrationsleerlauf (Supermarktkasse, Stau, usw.) gecheckt
- Für Facebook, Twitter u.ä. gilt das gleiche
- Die Anzahl möglicher Tabs im Browser ist durch ein Plugin auf 8 begrenzt
- Gedanken, Ideen und Notizen werden mit Tags und Kategorien versehen in Evernote gespeichert. So kann ich sicher gehen, nichts zu vergessen.
Die Infografik der Open Universities erklärt zunächst exzellent, warum Multitasking für das Gehirn nicht funktioniert und schlägt abschließend noch folgende Taktiken vor:
- Aufgaben zusammenfassen: Mehrere Mails in einem Rutsch beantworten und die Lieblingswebseiten per RSS-Reader auf einen Schlag lesen
- Tech-Freie Zeiten mit Freunden und Familie festlegen, in denen man einfach mal offline ist
- Hinweis in Signaturen und in Web-Profilen, zu welchen Uhrzeiten man erreichbar ist.
Und wie werden Sie dem Multitasking und Informationoverflow Herr und vermeiden digitalen Stress?