Jedes Mal aufs Neue, sobald sich die Anzeige des Google PageRanks verändert, diskutieren die Seo- und Marketingexperten darüber, welche Wertigkeit der PageRank in der heutigen Zeit besitzt.
Rückblick in die Anfangszeit des PageRank Algorithmus
Der Google PageRank-Algorithmus stammt, wie der Name eigentlich schon sagt, aus dem Hause von Google und diente als Grundlage der modernen Suchmaschine.
Die Aufgabe des PageRank-Algorithmus war die Qualität von Internetseiten anhand ihrer Linkpopularität, also Links die auf eine Webseite verweisen, zu gewichten und Webseiten anhand der Bewertung in den Serps (Suchergebnissen) zu positionieren. Im Hinterkopf sollten wir dabei aber behalten, dass der Algorithmus weitaus komplexer ist, als wir ihn hier dargestellt haben.

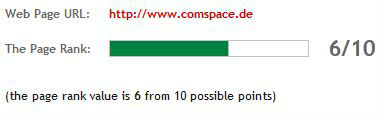
Der öffentliche PageRank wird in einer Skala von 0 bis 10 dargestellt. Webseiten mit einem hohen PageRank wurde lange Zeit nachgesagt, dass diese von der Qualität besser sind als Webseiten, die einen niedrigeren PageRank besitzen. Das Problem dabei war nur, dass der PageRank aufgrund des Linkhandels manipuliert werden konnte und deshalb kein ausreichendes Qualitätsmerkmal für gute Inhalte darstellte.
Linkhandel – Linktausch und Linkverkauf
Aufgrund dessen, dass relativ schnell klar war, welche Bedeutung der PageRank hat, erlebte der Linkhandel einen Aufschwung und Links/Backlinks wurden in verschiedenen Formen gehandelt.
Dem entsprechend wurde auch viel Kritik an dem PageRank laut, da finanzkräftige Unternehmen in der Lage waren Backlinks zu kaufen. Mittlerweile verstößt der Handel mit Links, ob Kauf oder Tausch, gegen die Google Webmasterrichtlinien.
Google hat sich nicht nur als Unternehmen durch viele seiner Dienste wie GoogleMail oder GooglePlus weiterentwickelt, auch der Google Algorithmus ist mittlerweile deutlich größer und facettenreicher als zu Zeiten, wo der PageRank einer der wenigen Qualitätsmerkmale war. Besonders durch diverse Algorithmus Updates wie zum Beispiel das Panda Update (einst auch Farmer Update) und Pinguin Update versucht Google auf Basis der eigenen Webmasterrichtlinien den Handel mit Links zu unterbinden und die Qualität in den Vordergrund zu rücken.
Warum Google an dem PageRank festhält
Im Online Marketing wird häufig die Frage gestellt, warum Google überhaupt an dem PageRank festhält, wenn doch bekannt ist, dass dieser sich ggf. auch noch heute manipulieren lässt und dadurch der Linktausch gefördert wird.
Google wird sicherlich nicht aus dem Grund des Linkhandels an dem PageRank festhalten – sondern weil der PageRank noch ein Teil eines großen Algorithmus zur Bewertung von Webseiten und eben nicht mehr das Alleinstellungsmerkmal für qualitative Webseiten ist, aber dennoch als ein Kriterium von sehr vielen in die Bewertung von Webseiten einfließt.
Trotz aller Theorien – ohne eine 100 %ige konkrete Aussage von Google wird diese Frage nie zur vollsten Zufriedenheit aller beantwortet werden können.
Aktualität des sichtbaren PageRanks
Ein weiteres Problem ist die Aktualität des PageRanks – während sich Suchmaschinenoptimierer oder Suchmaschinenmarketing-Experten stets auf aktuelle Daten verlassen wollen bzw. sogar müssen, so ist der sichtbare PageRank, im Gegensatz zum internen PageRank, nie wirklich aktuell.
PageRank Updates werden in der Regel alle drei bis sechs Monate durchgeführt und viele Webseitenbetreiber erfreuen sich daran, dass sich der PageRank ihrer Seite ggf. verbessert oder überhaupt einen bekommen hat.
Doch gerade im Update-Intervall liegt das Problem – ist der PageRank am Tage des Updates tatsächlich aktuell oder hat der Google Algorithmus den PageRank bereits Wochen zuvor berechnet und diesen erst am Tage des Updates sichtbar für alle Webseitenbetreiber gemacht?
Google Panda und Google Pinguin Update
Wie bereits im Abschnitt “Linkhandel – Linktausch und Linkverkauf” beschrieben, arbeitet der Suchmaschinenbetreiber Google stets daran, die Qualität seiner Suchergebnisse zu verbessern. Dem entsprechend gab es in den vergangenen Wochen und Monaten einige Updates wie zum Beispiel das Panda Update und das Pinguin Update.
Des Weiteren hat Google viele Linknetzwerke, die einzig und allein zum Zweck des Backlinkhandels hochgezüchtet wurden, deutlich abgewertet und teilweise deindexiert.
Ist der PageRank tot?
Beim Google PageRank kommt ein Spruch besonders zum Tragen: „Tot Gesagte leben länger.“ In der Vergangenheit wurde der PageRank immer mal wieder tot geredet – doch ist der PageRank tatsächlich tot?
Meines Ermessens ist der PageRank nicht tot, sondern er ist zum einen ein Bestandteil eines großen Algorithmus zur Verbesserung der Qualität in der Suchergebnissen und zum anderen kann ich mir gut vorstellen, dass der PageRank aufgrund der Deindexierung und Abwertung von Blocknetzwerken eine Wiedergeburt erlebt.
Wenn Google in der Lage ist, sogenannte Blognetzwerke zu erkennen und diese entsprechend aus der Bewertung von Webseiten herauszufiltern, so erlaube ich mir die Theorie aufzustellen, dass der PageRank nicht tot ist, sondern aus seinem langen „Winterschlaf“ erwacht.
Die vergangenen fünf PageRank Updates
- PageRank Update am 03.05.2012
- PageRank Update am 07.02.2012
- PageRank Update am 07.11.2011
- PageRank Update am 22.07.2011
- PageRank Update am 27.06.2011
Eine komplette Historie der PageRank Updates findet sich hier.