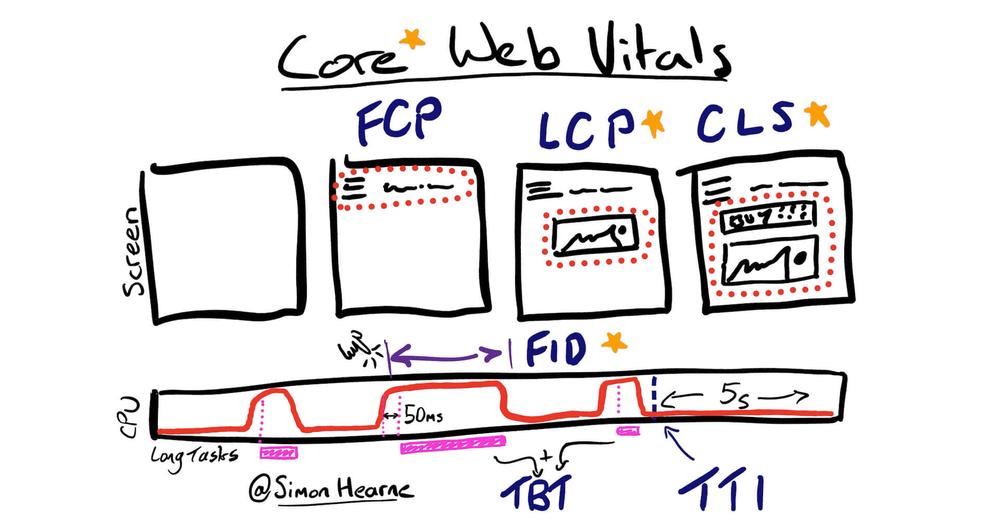
Google hat letzte Woche seine Webmaster Rules für Linktauschprogramme geändert, wie SiliconvalleyWatcher Tom Foremski bei ZDnet schreibt. Tom sieht in den Änderungen besonders einen Angriff von Googles auf PR-Agenturen. Ich denke, seine Erkenntnisse sind weit reichender und lassen sich auf jede Webseite übertragen, die Inhalte verbreiten und Traffic kanalisieren und Besucher anziehen will.
Google hates any other business that promotes other businesses because Google wants that money.
Das ist seine Kernaussage – nicht ganz wörtlich übersetzt: Google wird langfristig gegen alle Unternehmen vorgehen, die andere Unternehmen online promoten. Weil Google diese Kohle selber haben will. Und weiter heißt es, dass Pressemitteilungen eine Form von SEO sei. Ob die PR-Industrie diese Ansicht teile oder nicht sei dabei irrelevant, weil Google hier die Definition, den Umgang damit und etwaige Sanktionen festlegt.
Was ist denn jetzt eigentlich genau das Problem mit Pressemitteilungen?
Bis heute hat Google weder eigenes Marketing betrieben, um sich als beste Suchmaschine zu positionieren, noch hat Google einen Marketing-C-Level im Organigramm stehen und – wie Foremski feststellt – ist Google sehr stolz darauf, dafür zu sorgen, dass sie zur Selbststeuerung des Internet beitragen, indem automatisch immer die besten Suchergebnisse nach oben kommen. Das funktioniert natürlich nur so lange, wie (verdeckt) bezahlte Werbeangebote nicht die Ergebnisse verfälschen.
Soweit zur Google-Romantik und dass es qualitativ hochwertige Suchergebnisse bieten will. Auf der anderen Seite der Medaille steht ja noch etwas anderes, sehr nachvollziehbares: Google will AdWords verkaufen. Je besser die inhaltlichen Suchergebnisse, desto besser funktionieren auch die AdWords. Doof, wenn Agenturen Budget von AdWords abziehen, dass dann in bezahlte Beiträge fließt, die wiederum die Suchergebnisse verschlechtern. Quasi eine Lose:Lose-Situation für Google.
Früher bedeutete Qualität v.a. Anzahl von Links auf eine Seite. Je mehr unabhängige Links, desto höher rankte die Seite. Dann kam das Panda-Update und damit der stärkere Fokus auf Qualität. Das bedeutete: Bezahlte Links und SEO-Tricks wurden ausgesiebt, Usability und schnelle Ladezeiten trugen zur Qualitätssteigerung und damit zur Verbesserung des Suchrankings einer Seite bei. Die reine Anzahl an Backlinks wurde zum ersten Mal in den Hintergrund gedrängt.
Mit dem Penguin-Update und Penguin 2.0 wurde der Fokus noch weiter auf externe Linkqualität, Link- und Ankertexte innerhalb von Webseiten gelegt sowie auf den strukturierten Aufbau von Webinhalten und deren Verbreitung durch Social Signals – hierzu hat ein Kollege eine 5-teilge Artikelserie geschrieben.
Was machen PR-Agenturen in Googles Augen falsch?
Sie verwässern und verschlechtern die Suchergebnisse durch gezielt platzierte Gast-Beiträge, bezahlte Beiträge in Blogs, Advertorials, bezahlten Twitter- und Facebook-Shares, gekauften Followern etc. Hier die drei neuen Punkte, die der Google Webmaster Doku hinzugefügt wurden:
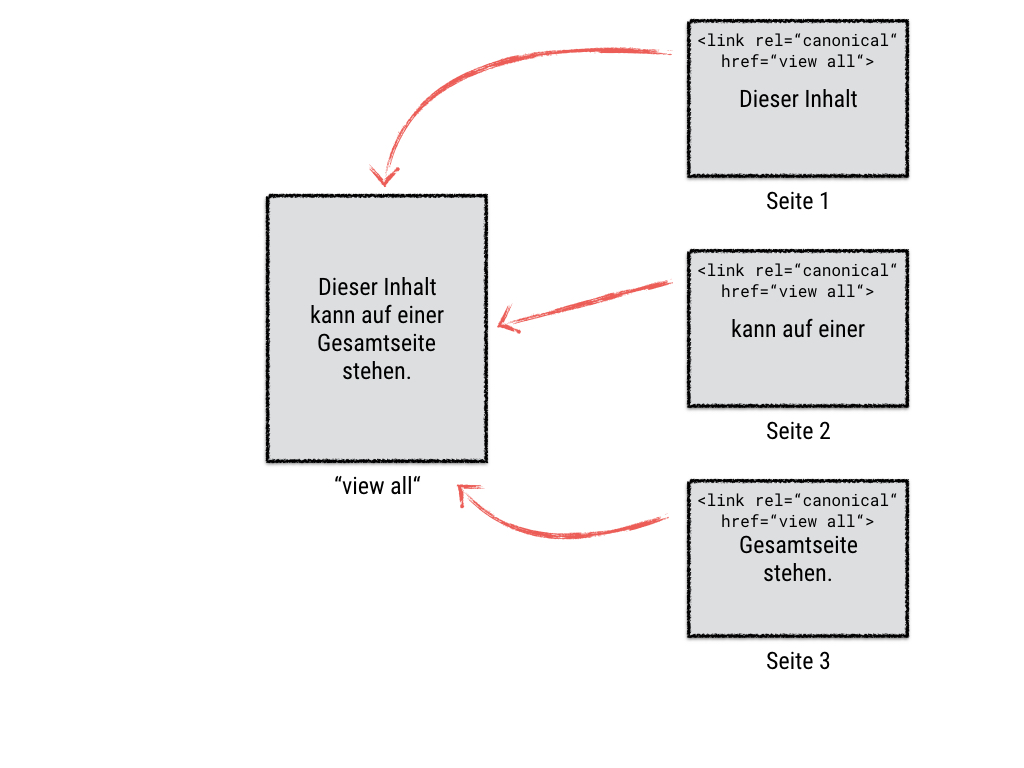
- Links mit optimiertem Ankertext in Artikeln oder Pressemitteilungen, die auf anderen Websites verteilt sind. Beispiel:
Das Angebot an Trauringen ist riesengroß. Wenn Sie eine Hochzeit planen, suchen Sie sicher nach dem besten Ring. Sie müssen auch Blumen kaufen und einHochzeitskleid.
- Artikel-Marketing im großen Stil oder das Posten von Kampagnen als Gast mit Ankertextlinks, die viele Keywords enthalten
- Textanzeigen oder native Werbung, wo Artikel mit Links, die PageRank weitergeben, bezahlt werden
Für mich persönlich sind besonders die Wortwiederholungen ein Graus. Der gleiche Abschnitt zum Trauring-Beispiel aus den englischen Webmastertools macht das mit 3 mal „wedding“ und 2 mal „ring“ auf insgesamt 32 Wörter deutlicher:
Sie merken schon: Man merkt beim Lesen einfach selber, wann man es mit der Optimierung übertrieben hat 😉
Das Beispiel aus der Dokumentation zu „Forumkommentare mit optimierten Links im Post oder in der Signatur“ treibt es auf die Spitze:
Haben Sie also ein gutes Auge darauf, was Ihnen Ihre Agentur genau anbietet und in Ihrem Namen veröffentlicht – Letztendlich straft Google voraussichtlich v.a. den Kunden einer Agentur ab.
Betrifft das Problem nur PR-Agenturen?
Natürlich betrifft es im Kern- und Tages-Geschäft PR-Agenturen deutlich stärker als Unternehmen, die sich rein auf eigene Inhalte konzentrieren können. Aber auch hier kann es nicht schaden, für das Thema zu sensibilisieren und regelmäßig einen Blick in die Dokumentation von Googles Webmastertools zu werfen.
Doch die neuen Regeln werden mit ziemlicher SIcherheit auch auf bestehenden Content angewendet. Daher liegt es im eigenen Interesse die bestehenden Inhalte zu prüfen und ggf. nachzusteuern.
Tom Foremski malt für PR-Agenturen in den USA sehr, sehr schwarz, sieht sie in direkter Konkurrenz zu Google und stellt sogar in den Raum, Agenturen könnten von ihren Kunden verklagt werden, wenn durch die neuen Regeln nachträglich ein Schaden entsteht. Doch auch die zukünftige Arbeit wird nicht unbedingt erleichtert, wenn das Penalty-Damoklesschwert über jeder bezahlten Promotion schwebt. Die meisten PR-Profis in den Kommentaren des ZDnet-Artikels sind da deutlich entspannter.
Als jemand, der regelmäßig mit Google-Mitarbeitern aller Hierarchiestufen spricht gibt Tom den Rat: „Optimiert für Eure eigenen Kunden, damit die Suchmaschinen sich selber optimieren können“. Da ist durchaus etwas dran. Je besser die Webinhalte sind und je weniger Manipulationsversuche unternommen werden, desto mehr kann sich auch der Suchmaschinenanbieter auf sein Kerngeschäft konzentrieren, statt Zeit und Ressourcen in ein Katz-und-Maus-Spiel investieren zu müssen.
Meine persönliche Einschätzung ist, dass Google in den kommenden Monaten noch deutlich härtere Bandagen anlegen wird. Oder formulieren wir es so: Die Bandagen werden verfeinert, wenn nämlich der große Wust an massenhaften Presseportalmeldungen in den Griff bekommen wurde.
Denn wie gesagt: Es sieht jeden als Konkurrenten, der AdWords-Budget angreifen könnte.
Muss man mit Gastbeiträgen und Linktausch vorsichtiger werden?
Massive Kollateralschäden für alle Webseitenbetreiber sind derzeit eher nicht zu befürchten. So lange Beiträge einen Mehrwert liefern und nicht massiv in großer Zahl Links aufgebaut werden, sollte sich die Gefahr für einzelne Websitebetreiber in Grenzen halten wie SEOsweet hier auch im letzten Abschnitt beschreibt. Google geht es darum, systematische Massenverbreitung von Inhalten zu verhindern, deren einziger Zweck es ist, gezielt Suchergebnisse zu beeinflussen. Die Internetkapitäne raten dazu, die entsprechenden Methoden maßvoll einzusetzen.
Bleibt nur zu hoffen, dass Google gut unterscheiden kann, wo ein eigener und eigenständiger Beitrag aufhört und eine Pressemitteilung anfängt.