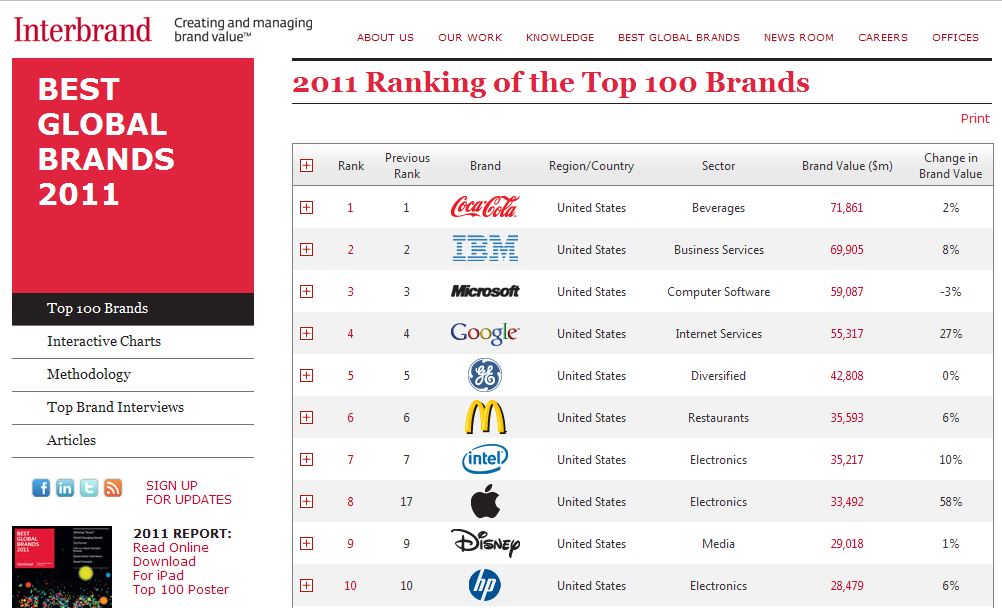
Fragt man den Chef eines mitelständischen Unternehmens, was er mit SEO erreichen will, wird man wohl meistens hören:
„Mehr Besucher auf der Homepage“ oder „Auf Platz eins der Google Suchergebnisse stehen“.
Mal abgesehen davon, dass diese Aussagen keine sonderlich gut definierten Ziele sind, könnten es sogar sehr ineffiziente Ziele sein.
Comspace ist unter anderem eine SEO/SEM Agentur. Durch einen Beitrag über SMARTe Ziele im allgemeinen Projektmanagement, den ich letztens für einen anderen Blog schrieb, begann ich mir Gedanken darüber zu machen, wie sich Ziele für SEO-Projekte definieren lassen.
Ein Projekt ohne vorher klar definierte und messbare Ziele ist in vielen Fällen zum Scheitern verurteilt. Denn: Wie soll man wissen, ob ein Projekt erfolgreich ist, wenn man den Erfolg gar nicht messen und erkennen kann?
Was bedeuten SMARTe Ziele?
Die Wikipedia erklärt wie Ziele nach dem SMART Prinzip sein sollen recht gut, daher hier die Kurzfassung:
S – Spezifisch und eindeutig definiert. Nicht vage und missverständlich
M – Messbar nach vorher festgelegten Größen. Mindestens eine Veränderung in Prozent
A – Akzeptiert von den Projektteilnehmern
R – Realistisch und erreichbar. Zu hohe Ziele frustrieren, zu niedrige Ziele führen zu unbefriedigenden Leistungen
T – Terminiert und festgelegt, wann welches (Teil)-Ziel erreicht sein soll.
Ein Ziel definiert also anhand von Zahlen, daten Fakten, was wir mit einem Projekt erreichen wollen. Im Falle eines SEO-Projektes könnte ein SMARTes Ziel also lauten:
- Die Sichtbarkeit des Projekts BEISPIEL im SEOTool-Index soll im Wettbewerbs-Umfeld im nächsten halben Jahr um mindestens 15% gesteigert werden.
- Das Ranking in den Suchergebnissen zu den Keywords X, Y und Z soll in 3 Monaten um mind. 3 Positionen durch die Maßnahmen 1, 2 und 3 verbessert werden.
- Die Conversion-Rate im Online-Shop in der Produkt-Kategorie TEST soll in 8 Wochen durch optimierte Ad-Words Begriffe um 5% erhöht werden.
Und sonst geht ja immer noch das: 🙂
http://www.youtube.com/watch?v=f0H6CUxfLF8
Doch wie legt man überhaupt SMARTe SEO-Ziele fest?
Zunächst einmal sollte man sich darüber klar werden, welche Produkte und Dienstleistungen durch entsprechende SEO-Maßnahmen gepusht werden sollen. Macht es Sinn, die „Renner“ weiter zu stärken? Oder kann die Position der „Penner“ verbessert werden?
Welche Alleinstellungsmerkmale und Produkt-Features sollen besonders hervorgehoben werden? Zum Beispiel könnte eine bestimmte Serviceleistung in der lokalen Umkreissuche stärker positioniert werden als deutschlandweit.
Wenn wir einen Überblick bekommen, womit wir es überhaupt zu tun haben, geht es an eine Keyword-Analyse. Welche nützlichen Keywords sind einfach und mit wenig Aufwand zu besetzen und welche sind hart umkämpft?
Eine Wettbewerbsanalyse bringt an den Tag, welche Seiten ein gutes Verhältnis zwischen Suchrankingergebnissen und Conversion-Rate haben. Welche Seiten ranken zwar hoch, performen aber weniger gut. Umgekehrt: Welche Seiten tauchen weiter unten im Ranking auf, schöpfen aber trotzdem eine gute Konversions-Rate ab?
Eine genaue Kunden-Analyse zeigt, woher – also über welche Links, Seiten und Keywords – Kunden kommen und welche Quellen in den Messgrößen, die für uns wichtig sind, am besten performen. Es würde uns ja wenig nützen, wenn wir mehr Besucher anziehen, diese aber nichts kaufen oder sich nicht bei unserem Vertrieb melden, um ein Beratungsgespräch zu vereinbaren. Stärken wir diese Quellen weiter oder öffnen wir neue?
Anhand dieser Informationen werden Maßnahmen abgeleitet, mit denen wir die einzelnen Faktoren beeinflussen können. Natürlich immer mit sinnvollen Messgrößen versehen, damit wir schnell Veränderungen feststellen und entsprechend unserer Ziele nachsteuern können.
Die Vorteile dieser festgelegten Ziele liegen auf der Hand:
- Durch genaue Vorab-Definition werden Fehlentscheidungen vermieden
- Im Projektverlauf kann schneller erkannt werden, welche Maßnahmen fruchten und auf welche verzichtet werden kann
- Die eingesetzten Mittel werden effektiver genutzt und Kosten gering gehalten
- Die Kommunikation innerhalb des Projekts ist eindeutig und verständlich für alle