OSO 7.0 Oliver Berger von ubermetrics zu Social Monitoring (c) Sven Linneweber
Der letzte Online Stammtisch OWL war bereits die siebte Ausgabe und wie schon beim 5. „OSO“ fand die von uns gesponsorte Veranstaltung mal wieder in der Bielefelder Schueco-Arena statt. Neben dem allseits beliebten Speednetworking und dem sportlichen „Rahmenprogramm“, dem 2.Liga-Spiel Arminia Bielefeld gegen den 1.FC Köln standen spannende Vorträge auf der Agenda:
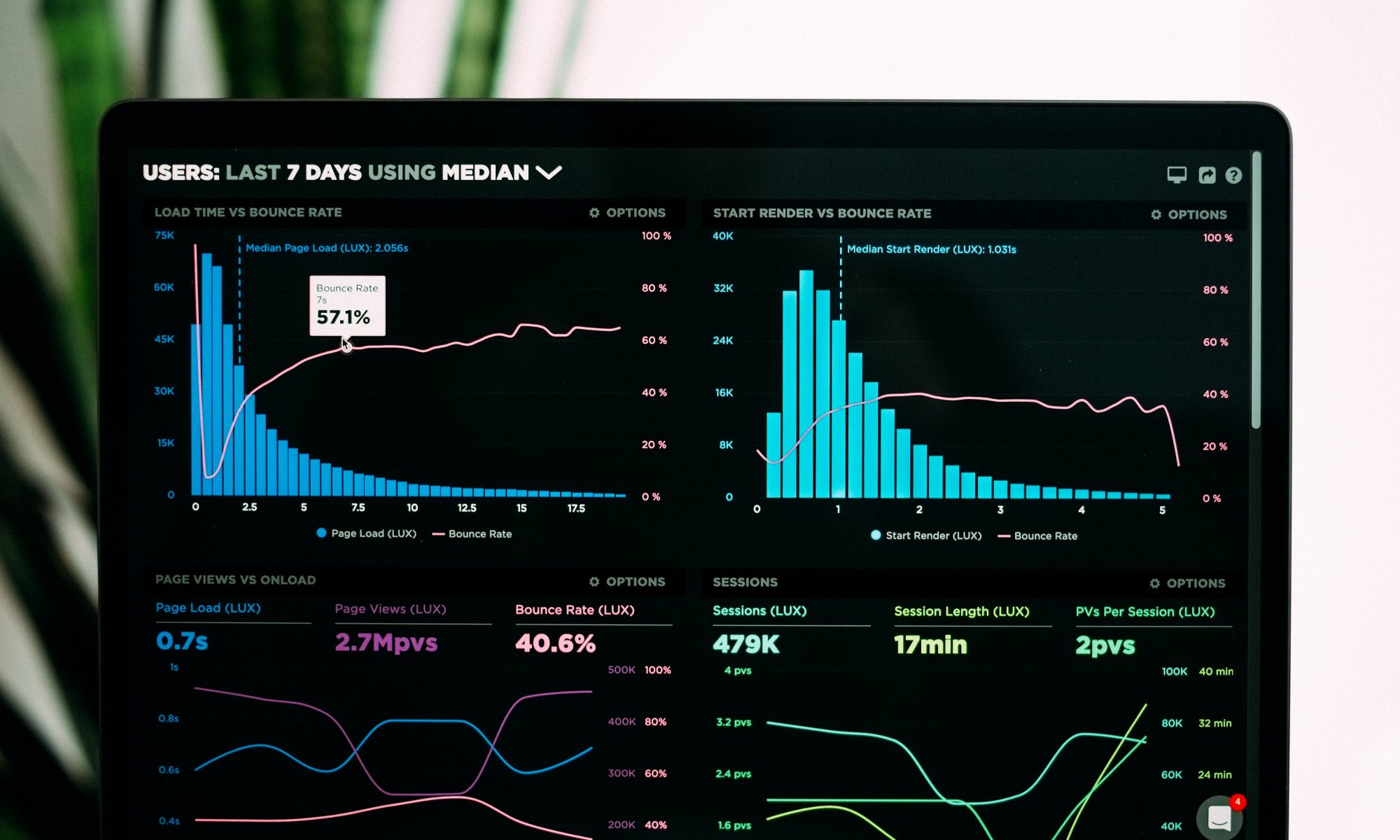
Social Monitoring – Oliver Berger, ubermetrics
Wissen Sie, was in Medien und Social Web über Ihr Unternehmen, Ihre Produkte und Marken oder sogar Ihre Person gesprochen wird? Oliver Berger erklärte uns in knapp 15 Minuten, was Social Monitoring ist, was es kann, worauf besonders geachtet werden muss und zeigte was das Tool ubermetrics alles kann am Live-Vergleich:
Was wird über Arminia Bielefed und den 1.FC Köln ganz aktuell im Social Web und den klassischen Medien gesprochen?
Vor dem wichtigen Spiel gegen den 1.FC Köln hatte uns Tim Santen (Medien & Kommunikation beim DSC Arminia Bielefeld) einen kleinen Eindruck von der Social Media Nutzung des Vereins gegeben, der beim diesjährigen Fanpage-Awardvon TNS Infratest und der WuV einen tollen 11. Platz (von 276 Teilnehmern) erreicht hat!.
Big Data war schon 2012 ein vieldiskutiertes Thema. Auch ein namhafter CMS Hersteller und ein Anbieter von Webanalyse-Lösungen griffen bereits das Thema auf. Grund genug für uns zu schauen, was hinter dem Begriff steckt und wo wir als Online-Dienstleister Berührungspunkte sehen sowie die Frage zu stellen: Ist Big Data auch ein Thema für Mittelstand und Nicht-Online-Unternehmen?
Stellen Sie sich den Weltraum vor. Irgendwo im Universum des Webs gibt es ein (im Vergleich zum großen Ganzen) kleines Sonnensystem, das Ihre Kommunikationskanäle repräsentiert. Um das Zentrum rotieren Content-Planeten wie Twitter, Facebook, YouTube, XING, Pinterest und was immer sonst Ihr Unternehmen zur Verbreitung von Inhalten nutzt, um die Kunden zu begeistern und neue Leads und Geschäftsabschlüsse zu erzeugen.
Schauen wir uns einfach mal ein paar Zahlen zum Web an, die uns ein Gefühl dafür geben, in welchen wortwörtlich astronomischen Bereichen wir uns eigentlich bewegen (Quelle seo-united.de):
246 Millionen Domain-Registrierungen
634 Millionen Webseiten
15 Millionen .de Domains
1,1 Milliarden Besucher auf Facebook monatlich
2,7 Milliarden Facebook Likes täglich
175 Millionen Tweets – ebenfalls täglich
1,2 Billionen Suchanfragen bei Google
5 Milliarden Instagram Fotos insg.
1 Milliarde Views auf „Gangnam Style“
Unsere Aufgabe im Online Marketing besteht unter anderem darin, aus diesem Wust an Interaktionen und den Aufmerksamkeitspartikeln im Web einen kleinen Teil der potenziellen Kunden auf unsere Inhalte zu ziehen.
Die einzelnen Bestandteile unserer Online-Sternen-Systeme sind dabei so individuell wie Ihre Kundenstruktur oder Ihr Produktportfolio. Jeder „Social-Web-Planet“ funktioniert nach seinen eigenen Naturgesetzen, zieht seine eigene Zielgruppe an und hat seine eigenen Regeln für die Darstellung von Inhalten. Doch eines haben alle gemeinsam: Sie drehen sich um das Zentrum Ihres Webauftritts:
Ihre Website im Zentrum der Social Media Strategie
Ob Sie eine einzelne Firmen-Website haben, einen umfangreichen Shop, ein internationales Netzwerk aus Brand-Pages oder eine Kunden-Community: Auf Ihrer Unternehmens-Website laufen alle Ihre Kommunikations-Fäden und Interaktionen zusammen. Hier werden Unternehmensinformationen, E-Commerce-Angebote, Micro- und Landingpages angeboten und internationale, multilinguale Produkt-Informationen verwaltet. Von hier gehen alle inhaltlichen und geschäftlichen Impulse aus. Hier legen Sie weitestgehend die Regeln und Naturgesetze fest.
Und: Die Website hat wie die Sonne im Zentrum eines Sternensystems eine eigene Anziehungskraft. Dabei ist es prinzipiell gleich, mit welchem System die Seite betrieben wird. Unsere konkreten Einsatz-Beispiele demonstrieren wir weiter unten am von uns angebotenen Sitecore CMS.
Ihre Website zieht nicht nur Besucher an. Sondern auch die bestehenden Mitarbeiter und neue Bewerber, Lieferanten und Geschäftspartner. Kunden-Feedback, Service-Fragen und Kommentare. Direkte Käufe oder Konversionen wie Newsletter-Anmeldungen oder Bestellungen von Whitepapern.
Diese Anziehungskraft kann auf unterschiedliche Art erzeugt werden:
Durch schiere Größe und Bekanntheit – dies trifft besonders auf klassische Marken wie Coca Cola, Nike u.a. zu
Durch einzigartige Funktionalität – an diesem Punkt befindet sich bspw. Google
Weil „alle anderen auch da sind“ – siehe Facebook
Durch gezieltes Decken bestimmter Zielgruppen-Bedürfnisse
Durch lehr-, hilfreiche und unterhaltsame Inhalte
Doch was baut diese Anziehungskraft überhaupt auf?
Neben der Markenbekanntheit, USPs und einzigartigen Funktionalitäten greifen viele Eigenschaften ineinander, um eine hohe Anziehungskraft für Ihren Web-Fixstern aufzubauen.
Die zentrale „Masse“ aus der sich alles zusammensetzt ist: Content.
Auf der Meta-Ebene besteht Content ganz einfach aus Text, Zahlen, Bildern, Audio und Video. Im Detail gibt es vermutlich so viele feine Abstufungen und Abgrenzungen zwischen Inhalten, wie es Sterne im Universum gibt.
Zunächst sollte der Content natürlich auf Ihre Marke und Ihre Produkte abgestimmt sein. Die Inhalte erklären wofür Ihre Marke steht, wie und warum Ihre Produkte und Leistungen für Ihre Kunden hilfreich und begehrenswert sein können. Unterhaltungswert und Mitmach-Faktor sorgen dafür, dass Kunden sich einbringen, Inhalte weiter verteilen und Ihnen Feedback geben. Ihr Umgangston und das „Ambiente“ der Inhalte sorgt für eine emotionale Anziehungskraft: Wenn Sie in der Healthcare-Branche arbeiten, vermitteln Ihre Inhalte natürlich eine andere Gefühls- und Werte-Welt als bspw. die eines Tourismusunternehmens oder Lebensmittelherstellers.
Die Art der Veröffentlichung und Verteilung von Inhalten wirkt sich ebenfalls auf seine Anziehungskraft aus. Ihr Content sollte natürlich so lange wie möglich „wirksam“ bleiben. Demnach macht es in vielen Fällen Sinn, Inhalte in kleinere „Happen“ aufzuteilen und episodisch zu veröffentlichen, um die Erwartung beim Adressaten zu erhöhen und regelmäßig neues „Futter“ zu liefern.
Dabei macht es Sinn, unterschiedliche Kanäle auf unterschiedliche Arten zu nutzen. Bietet sich Twitter bspw. an um Multiplikatoren, Medienvertreter und Experten Ihrer Branche direkt anzusprechen, ist Facebook möglicherweise eher der direkte Weg zum Endkunden. Sogar eine mehrstufige Verteilung ist denkbar:
Veröffentlichung eines Blogbeitrags
Diskussion des Beitrags auf Facebook mit der Zielgruppe
Zusammenfassung der Erkentnisse in einem Artikel auf der Website
Verbreitung der komprimierten Erkenntnisse auf der Website via Twitter und Google+
Mit die wichtigste Eigenschaft von anziehendem Content sind die Alltagstauglichkeit für den Kunden, leichte Auffindbarkeit und Teilbarkeit und nicht zuletzt persönliche Ansprache und Spaß. Dann lassen sich die erstrebenswerten Effekte erzielen:
Welche Ziele soll anziehender Content erreichen?
Natürlich gibt es zahllose KPI, Messfaktoren und Erfolgsindikatoren, die in unterschiedlichen Abstufungen ausgewertet und erreicht werden können. Zur einfacheren Verdeutlichung möchte ich diese 5 Kern-Ziele anführen:
Besucher auf Website bringen
Besucher dort halten
Anfragen, Feedback, Konversion erzeugen
Besucher zum Teilen inspirieren
Zu Rückkehr & Empfehlung animieren
Wie wird solcher Content erzeugt?
Auch hier könnte ich mehrere Artikel über die Planung und Erstellung von Content für die verschiedensten Zielgruppen, Kanäle und Branchen schreiben (bei Bedarf tue ich das sogar sehr gerne! Einfach einen kurzen Kommentar hinterlassen, welches Themengebiet Sie besonders interessiert) – heute möchte ich mich auf 7 zentrale Punkte konzentrieren:
Was sollen die Kunden tun?
Was müssen die dazu Kunden wissen und was ist darüber hinaus interessant / unterhaltsam?
Wer sind die Kunden / Welche Personas sollen angesprochen werden?
Content-Strategie mit Veröffentlichungs-Plan erstellen – wann wird welcher Inhalt veröffentlicht, um was damit zu erreichen?
Inhalte erstellen
Promotion für den Content
Messen, erforschen & weiter entwickeln
Erforschen & weiter entwickeln der Sitecore Website
An diesem Punkt kommen wir von einer sehr allgemeinen Sichtweise zur sehr speziellen. Es gibt dort draußen unglaublich viele Werkzeuge zum Monitoring, Analysieren und Reporting für Webseiten.
In diesem Beispiel fokussieren wir uns auf die Eigenschaften und Fähigkeiten unserer „Sonne“. Dem eingangs erwähnten zentralen Fixpunkt in unserem eigenen Web-System: Dem Enterprise CMS Sitecore.
Sitecore bietet eine exzellente Kombination aus Anbindungen an externe Kanäle, Auswertungs- und Test-Werkzeugen und Möglichkeiten neuen Content zu erstellen der individuell auf identifizierte Nutzergruppen zugeschnitten werden kann, bis hin zu persönlichen Individualisierbarkeit für einzelne Kunden.
Mit dem Digital Marketing System DMSlassen sich bsw. A/B-Tests durchführen, um verschiedene Darstellungsformen, Werbe-Grafiken, Call-to-Actions und Inhaltstypen auf ihre Wirkung zu testen. In Kombination mit Erkenntnissen über das Nutzerverhalten lassen sich Konversions-Raten und deren Qualität verbessern (bspw. durch Verringerung von Rücksende-Quoten).
Sitecore bringt in der Version 7 Werkzeuge mit, durch die sich bspw. Produkte, Leistungen und Inhalte in Item-Buckets individuell zusammenstellen und als ein kontextbasiertes Inhalte-Paket anbieten lassen. Ebenso können im Backend vom Produkt-Manager zusammen gestellte Suchen als SEO-optimierte und dynamische Landingpage erzeugt und mit Zusatzinformationen versehen werden. Content Boosting sorgt dafür, dass Premium-Inhalte Ihrer Webseite prominent dargestellt werden um bspw. dafür sorgen, dass Ihre Kunden stärker und länger mit Ihren Inhalten interagieren und letztlich die Konversionsrate erhöhen.
Wie bauen wir Anziehungskraft auf Social Web Kanäle auf?
Hierfür gibt es natürlich tausende Möglichkeiten. Die althergebrachte wäre Inhalte über RSS-Feeds in die eigene Seite zurück zu holen. Über APIs (so vom Social Web Dienst angeboten) können wir individuelle Anbindungen von Sitecore an Social Web Dienste bauen.
Die interessanteste und auch für Produktmanager, die mit Sitecore arbeiten recht einfach zu lösende Möglichkeit ist, individuellen Content an Nutzer auszuliefern – je nachdem woher diese Nutzer kommen. Ein Beispiel:
Unser (noch anoynmer) Nutzer kam über einen Link auf Facebook (den einer seiner Freunde dort geteilt hat) auf unsere Seite. Sitecore erkennt im Hintergrund, dass der Nutzer von Facebook kommt und zeigt anstatt der Standard-Begrüßung „Willkommen auf unserer Website“ – eine individuelle Meldung: Hallo Facebook Nutzer! Willkommen auf unserer Website. Werden Sie doch Fan unserer Facebook-Page!“ Gefolgt von einem Like-Button.
Der Nutzer klickt auf Like, wird unser Facebook-Fan und im folgenden Surf-Verlauf auf unserer Website können wir weitere Interaktionen anbieten, mit dem wir die Bindung des Nutzers erhöhen, sie oder ihn besser kennen lernen und immer persönlich relevantere Inhalte an den Nutzer ausliefern.
Denn: Die eigene Website ist das Zentrum Ihres Web-Systems indem es Kunden anzieht, wie schon der gute alte Herr Newton wusste:
Gravitation ist nicht einfach eine gute Idee. Sie ist ein Naturgesetz.
PS: Und glauben Sie mir, als Social Media Manager und Fan des Social Web bin ich sogar ein bisschen wehmütig, einen Beitrag zu schreiben, der von meinem natürlichen „Lebens- und Arbeitsraum“ wegführt 😉 Aber die letzten 1 1/2 Jahre Arbeit bei comspace haben mir wieder vor Augen geführt, wie wichtig die eigene Webpräsenz auf lange Sicht ist, in der die eigenen Regeln gelten.
Die dmexco ist Fachmesse und Konferenz für die digitale Wirtschaft und findet am 18.9. und 19.9. in Köln statt.
Gemeinsam mit unserem Partner Sitecore sind wir dieses Jahr zum ersten Mal auf dem Stand C-056/C-058 in Halle 7 vertreten und werden uns mit 4 Vorträgen am Standprogramm beteiligen.
1 Plattform, 2 Marken, 9 Länder: Erfahrungen aus einem Großprojekt
Christopher Loos, Interwall Agentur für digitale Medien und Kommunikation GmbH
11:00-11:25
Corporate Websites: Mit Workflows mehrsprachige Multichannel-Projekte steuern Michael Steinfort, Geschäftsführer comspace
11:30-11:55
Weltweites Deployment von sitecore ohne eigene Infrastruktur – mit Windows Azure Joris Kalz, Technologieberater Microsoft Deutschland
Multichannel und Social Media
12:00-12:25
Responsive Design: Geräteoptimierte Darstellung mit Sitecore
Michael Steinfort, Geschäftsführer comspace
13:00-13:25
Social Media: Die Website als Zentrum Ihrer Social Media-Strategie
Alex Kahl, Social Media Manager comspace
Customer Experience
14:00-14:25
Engagement statt Newsletter
Thomas Golatta, Vorstand netzkern AG
15:00-15:25
Wege zu effektivem, kanalübergreifendem Digital Marketing
Tarek Lablack, Sitecore Deutschland GmbH
Analytics , Customer Intelligence und Strategie
16:00-16:25
Neue Chancen für den Kundendialog mit sitecore: Individualentwicklugen von Foren für das CRM.
Ulf Frankenfeld, team neusta GmbH
17:00-17:25
Marketingtechnologie effektiv nutzen: Mit Customer Experience zum ROI. Timo Wolters, Sitecore Deutschland GmbH
dmexco Vorträge Donnerstag, 19. September 2013
Web Content Management
10:00-10:25
1 Plattform, 2 Marken, 9 Länder: Erfahrungen aus einem Großprojekt
Christopher Loos, Interwall Agentur für digitale Medien und Kommunikation GmbH
11:00-11:25
Sitecore 7 – die neuste Version aus der Partnersicht
Markus Grün, Sitecore MVP und Chief Technical Officer netzkern AG
11:30-11:55
Hohe Performance und keine Ausfallzeiten trotz Spitzenauslastungen Ihrer WebsiteJoris Kalz, Technologieberater Microsoft Deutschland
Multichannel und Social Media
12:00-12:25
Responsive Design: Geräteoptimierte Darstellung mit Sitecore
Michael Steinfort, Geschäftsführer comspace
13:00-13:25
Auf dem Weg zum 1:1-Dialog mit emanzipierten Kunden: Tipps für Digital Marketer.
Ralf Schobert, Sitecore Deutschland GmbH
Customer Experience
14:00-14:25
Digital Marketing System – auf dem steinigen Weg zur perfekten Website Christopher Wojciech, Sitecore MVP und Head of Consulting netzkern AG
15:00-15:25
Kanalübergreifende Personalisierung: Auf dem Weg zum digitalen Marketing der Zukunft Dominik Bader, Sitecore Deutschland GmbH
Analytics , Customer Intelligence und Strategie
16:00-16:25
Wann ist sitecore die passende Lösung für mein Unternehmen? Eine Checkliste für Business Entscheider. André Schütte, Interwall Agentur für digitale Medien und Kommunikation GmbH
17:00-17:25
SEO und Sitecore – ein perfektes Team Taylan Demirkol, Online Marketing Consultant netzkern AG
„Mobile Webseite? Brauchen wir nicht. Wir haben ja keine Kunden, die unsere Leitungen von unterwegs nutzen. Unsere Webseite muss keine Touristen ansprechen, die auf der Suche nach einem Restaurant sind und auch keine hippen Jugendlichen, die auf einer Party „einchecken“ wollen.“
Wirklich nicht? 5 Gründe für eine mobile Webseite:
Letztens griffen wir hier die problematische Vielfalt mobiler Endgeräte auf. Im Umfeld dieses Themas möchten wir Ihnen auch einige Gründe nennen, warum eine mobile Webseite Sinn macht.
Wirrwarr mobiler Endgeräte auf der re:publica (cc) Gregor Fischer
1. Google legt immer mehr Wert auf mobile Webseite
Weiterleitungen sollten immer zu relevanten Seiten führen
nichtdarstellbares Flash auf mobilen Webseiten
Keine Umleitungen nur für bestimmte mobile Geräte
(Google Bot identifiziert sich aktuell interessanterweise als iPhone – sollte auch als solcher behandelt werden)
Videos, die in mobilen Endgeräten u.U. nicht laufen sind kritisch
Eine mobile Ausrichtung einer Seite kann sich sogar positiv auf das Suchergebnis auswirken
Dies ist nur die Spitze des Eisbergs. Wir gehen stark davon aus, dass die mobile Verfügbarkeit und Darstellbarkeit von Webseiten zukünftig immer relevanter für hohe Positionen in Suchergebnissen werden wird.
2. Mobile Suchvorgänge finden nur zu kleinem Teil von unterwegs statt, oder?
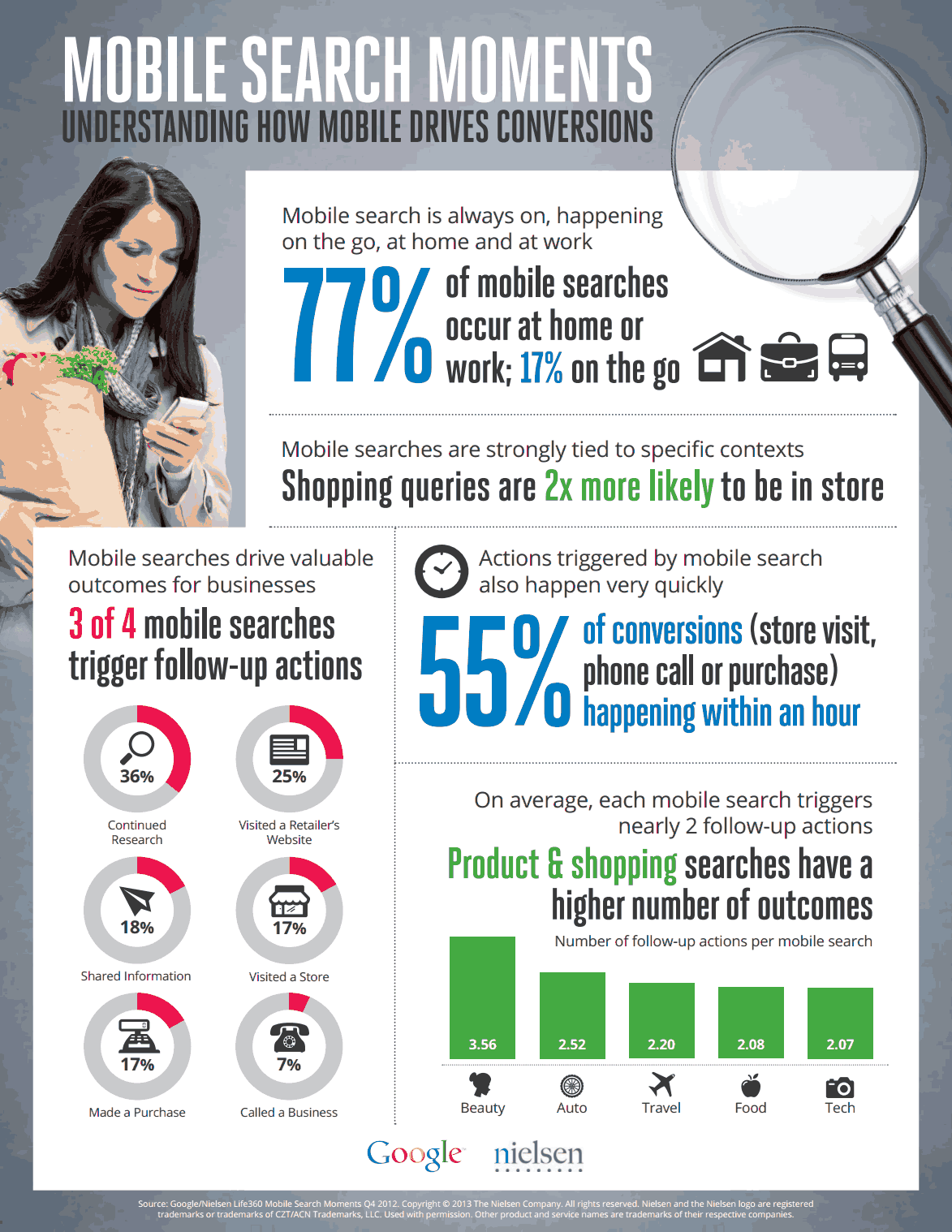
Was schätzen Sie, wie viele mobile Suchen überhaupt von unterwegs durchgeführt werden? Also auf Reisen, im Auto, während des Flanierens beim einkaufen? Ziemlich genau ein Viertel.
Gar nicht mal so viel, oder? Mich hat diese Zahl aus einer aktuellen Nielsen Studie jedenfalls sehr überrascht. Genau genommen werden 77% aller Suchen auf mobilen Endgeräten von zu Hause oder dem Arbeitsplatz aus durchgeführt. Wenn ich mich da mal selber als Zielgruppe beobachte, dann passt das sehr gut. Bevor ich das Notebook aufklappe um nach einem Produkt zu suchen, hole ich viel eher das Smartphone aus der Tasche. Der Zweit-Bildschirm, der abends auf der Couch genutzt wird, ist das Tablet.
(c) Google / Nielsen Group
3. Sind mobile Suchen denn wirklich schon relevant?
Relevanz zu definieren ist immer so eine Sache 😉 In diesem Fall möchte ich eine weitere Zahl aus der Nielsen Studie in den Ring werfen: 73% mobiler Suchanfragen lösen zusätzliche Aktionen und Konversionen aus und 28% führen direkt zu Konversionen:
36% führen zu weiterer Recherche des Kunden
25% führen auf eine Händlerseite
18% teilen Informationen weiter
17% führen direkt zum Kauf
17% beuschen ein stationäres Geschäft
7% resultieren in Anrufen
4. Mehrgeräte-Nutzung verbreitet sich immer mehr
Diese Infografik von Google zeigt sehr eindruckslvoll, wie stark typische Nutzungsszenarien auf mehreren Bildschirmen unterschiedlicher Größe durchgeführt werden:
Es geht also in den meisten Fällen gar nicht um die Optimierung einer Seite für einen bestimmten Kanal, sondern vielmehr um eine ganzheitliche Lösung, die alle Darstellungsoptionen wie Smartphone, Tablet, Ultrabook, Arbeits-PC und sogar Fernseher mit einbezieht.
5. Zukünftige Entwicklung mobiler Suchanfragen
Die Kollegen von gjuce haben hier einmal eine mögliche Entwicklung der Suchanfragen mobil vs. Desktop abgeleitet und in ein Kurvendiagramm gegossen. Ich würde hier nicht auf die exakte Nachkommastelle achten, halte den Trend aber für sehr realistisch:
Fazit: Prüfen Sie, welche Zielgruppe und Nutzungszenarien in Frage kommen
Dies waren 5 Gründe, die für den positiven Nutzen und die zunehmende Relevanz einer mobilen Webseite sprechen, auch wenn man nicht gerade Deutsche Bahn oder Lufthansa heißt.
Wenn Sie herausfinden möchten, ob sich eine mobil darstellbare Webseite für Ihr Unternehmen jetzt schon lohnen kann, sollten Sie sich die folgenden Fragen stellen:
Welche Handlung/Konversion soll beim Besuch Ihrer Webseite ausgelöst werden?
Wie sehen Ihre Zielgruppen aus?
In welchen Situationen nutzen diese Zielgruppen Ihre Webseite?
Welche Inhalte sollten mobil angeboten werden und welche nicht um die angestrebten Konversionen zu erreichen?
Sollte die bestehende Webseite „mobilisiert“ werden oder ein eigener mobiler Kanal eingerichtet werden?
In einem kürzlich erschienenen Blogbeitrag sind wir darauf eingegangen, warum eine automatisierte Migration von Inhalten beim Wechsel des Content Management Systems in der Regel nicht empfehlenswert ist. Denn meistens gehen mit der technischen auch strukturelle Veränderungen der Website einher: Die Navigationsstruktur wird geändert, Themenbereiche fallen weg, werden ergänzt oder an eine andere Stelle geschoben.
Hinweis: Wenn Sie wegen unsere Vortrags auf der dmexco 2014 auf diesen Beitrag gestoßen sind und Fragen zur CMS-Migration haben, können Sie hier gerne Kontakt zu uns aufnehmen.
Von Ausnahmen abgesehen. Eine solche Ausnahme haben wir anlässlich des Umzugs unserer Website auf ein neues CMS für uns in Anspruch genommen und einen Selbstversuch gestartet. Gründe für die automatisierte Content-Migration waren:
Es handelte sich bei uns um eine rein technische Migration unserer Website von einem CMS auf ein anderes. Inhalte und Strukturen blieben unverändert.
Mit dem Ziel, Erfahrungen mit einer Portierung zu sammeln, haben wir bei der Gelegenheit das Migrations-Tool Siteport getestet.
Aber beginnen wir von vorne:
Im Herbst 2012 haben wir beschlossen, unsere comspace-Website auf eine neue technologische Basis zu stellen: statt wie in den vergangenen Jahren die Website in OpenText zu pflegen, sollte dies zukünftig in dem Content Management System Sitecore geschehen. Warum Sitecore? Der CMS-Hersteller gehört lt. den Analysten von Gartner immer wieder zu den innovativsten und visionärsten WCMS-Anbietern und als Sitecore-Technologiepartner wollten wir das System nicht „nur“ bei unseren Kundenprojekten implementieren, sondern auch als Anwender einmal tiefer in die Materie einsteigen und zusätzliche Praxiserfahrungen sammeln (Lesen Sie weitere Details zu den Gründen für den CMS-Wechsel auf unserer Website).
Der Weg der Migration
Da Änderungen an Struktur und Inhalten unserer Website erst einmal nicht vorgesehen waren, handelte es sich nur um eine technische Migration der Seite. Um den Aufwand klein zu halten, wurde eine automatisierte Contentmigration als Weg geprüft. Unser Partner Oshyn (Los Angeles) hat für diesen Zweck das Modul Siteport entwickelt. Dieses beschlossen wir einmal zu testen, auch wenn das Modul damals einen noch rudimentären Entwicklungsstand hatte.
Über Web-Services stellt Siteport die Verbindung zwischen beiden Content Management Systemen her. Das System migriert dabei nicht nur Inhalte, sondern auch Templates, Nutzer, Gruppen, Workflows und Metadaten. Nach heutigem Stand unterstützt Siteport die Plattformen Sitecore, OpenText (RedDot), EPiServer, Drupal, Ektron und XML.
Einen kleinen Einblick in die Migration mit Hilfe von Siteport vermittelt das folgende Video.
Da das Migrationstool zu dem damaligen Zeitpunkt nur jeweils eine Sprachversion migrieren konnte (mittlerweile unterstützt Siteport auch Mehrsprachigkeit), konnten wir lediglich die englischen Texte automatisiert überführen und mussten die deutschen Texte manuell einpflegen. Trotz der hilfreichen und Zeit sparenden Unterstützung durch die Migrations-Software zeigte unser „Selbstversuch“, dass eine automatisierte 1:1-Migration mit Siteport (noch) nicht vollständig möglich ist. So werden verschachtelte Container-Strukturen von bspw. Slidern, Tabbing- oder Accordeon-Modulen in Sitecore anders abgebildet als in OpenText. Darüber hinaus konnten einige spezielle Feldtypen wie Datum oder URL noch nicht adäquat gemapped werden.
An dieser Stelle einen großen Dank an die Oschyn-Kollegen für die gute Zusammenarbeit: Über welches Problem auch immer unsere Entwickler stolperten, stets bekamen sie ein offenes Ohr und prompten Support von den Siteport-Experten.
Ein Traum: Das Telefon klingelt und der Kunde (B2B, weltweit agierend) „droht“ mit Auftrag. Ein Relaunch der Website soll es werden, auf einer neuen Technologie und sogar ein paar Ziele hat er bereits definiert: Top! Eine Websitemigration steht an.
Trotzdem wird es in einigen Fällen im Laufe des Projekts zu einer beliebten Diskussion kommen: Was passiert eigentlich mit den alten bzw. bestehenden Inhalten – kann man diese nicht einfach migrieren oder in der neuen Struktur zusammenführen?
Website-Migration
Diesen Zahn mussten wir unseren Kunden bis auf wirklich wenige Ausnahmen bisher immer(!) ziehen und es gibt auch sehr gute Gründe, weshalb eine Migration von bestehendem Content in den meisten Fällen nicht sinnvoll ist.
Websitemigration: Alter Wein in neuen Schläuchen?
Eine neue Website ist nicht unbedingt günstig und wenn man schon den einen oder anderen Euro für ein solches Projekt in die Hand nehmen möchte, dann bitte doch auch mit Sinn und Verstand. Oft ist das bestehende Projekt schon in die Jahre gekommen. Dadurch hat sich vielleicht auch das Marketing, die Kundenansprache, die Bildsprache, das Produktportfolio oder die Strategie des Unternehmens geändert. Diese neuen Umstände mit schon betagteren Texten und Bildern zu untermauern scheint nicht nur schwierig, es ist auch so.
Ein Relaunch einer Website sollte in der Konzeptionsphase auch immer eine Content Landscape und Sitemap mit berücksichtigen, sowie das vorgelagerte Erstellen von neuen Texten und Inhalten, das ganze bitte gemappt auf die konzipierten Module. Die Übernahme der erstellten Inhalte in das CMS im späteren Projektverlauf stellt im Idealfall eine reine Fleißarbeit dar: Bilder und Texte an die definierte Stelle mit einer definierten Vorlage einfügen.
Fazit: wenn Relaunch, dann aber auch bitte richtig, Alter Wein in neuen Schläuchen hilft keinem wirklich weiter.
Ein Importer ist komplex und teuer
Warum ein Importer so komplex und teuer ist? Das ist recht einfach zu erklären, wenn man sich die Features anschaut, die er so besitzen muss. Zunächst einmal muss der Content für die Websitemigration aus dem alten System heraus extrahiert werden. Im Idealfall gibt es einen Exporter, im Notfall könnte man auch noch aus statischen Seiten mit robustem HTML Dom Tree die Inhalte exrahieren. Wenn man Glück hat und die Formatierungen sind nur über Stylesheets vorgenommen worden, so besitzt man am Ende des Tages eine Sitemap, Texte und Bilder, dazu vielleicht ein paar interne Links, leere Stellen, an denen Funktionen integriert waren (Teaser, Linklisten, Ansprechpartner usw.).
Soweit zum einfachen Teil, dem Export.
Dazu haben wir bis auf eine einzige Ausnahme aber noch kein einziges Projekt erlebt, in dem wirklich nur die Technologie gewechselt und die Sitemap und die Inhalte 1:1 übernommen wurden. Wenn sich aber die Sitemap unterscheidet, dann fallen entweder Seiten weg, sie werden umsortiert oder ggf. zusammengefügt. Damit tut sich ein Automatismus schon im Grundsatz schwer.
Wenn es neue Module und Stylesheets gibt, dann gibt es vermutlich auch ein neues Layout mit neuen Bildformaten, denn zumindest an die neuen Browser und an eine optimale Darstellung auf mobilen Geräten mittels responsive Design sollte man seine Website trotzdem anpassen (auch wenn man “nur” die Technologie wechseln möchte). Die Verwendung der alten Bilder wird oftmals nicht möglich sein, daher müssen ggf. neue Bilder integriert werden.
Vielleicht liegen die neuen / alten Bilder jetzt aber auch (am besten nur teilweise) in einem MAM (Media Asset Management) und müssen extern referenziert werden. Über die Schnittstelle reden wir gar nicht erst, aber dass die Bilder so heißen wie man sich das vor ein paar Jahren mal überlegt hat, glauben wir alle erst einmal so nicht. Das gleiche gilt übrigens auch für andere Dokumente (Dokumentationen, Sicherheitsdatenblätter, Ausschreibungstexte, usw.)
Was wir an dieser Stelle auch einmal absichtlich außer Acht lassen, um es nicht unnötig kompliziert zu machen, ist die oftmals vorhandene Anforderung an Mehrsprachigkeit und die Wiederverwendung von Inhalten in mehreren Webseiten-Versionen (z.B. Länder-Auftritten).
Ein weiterer wichtiger Punkt ist die Suchmaschinenoptimierung der Website
Bestehende Metadaten wie Descriptions oder Seitentitel passen nach der Websitemigration eventuell nicht mehr und müssen optimiert oder ausgetauscht werden. Oder der Schwerpunkt wird auf andere Keywords gelegt, die sinnvoll in den Website-Texten platziert werden müssen.
Selbst wenn wir es also schafften, die vielen hundert Seiten mit einer Logik zu versehen, die die Seiten fachlich korrekt bearbeitet, Referenzen und Verlinkungen sicherstellt, dem neuen Layout entspricht usw., dann liegt nachträglich die Qualitätssicherung und Korrekturphase an, denn: zu 100% wird der Importer das gewünschte Ergebnis nicht herstellen können, vermutlich nicht einmal zu 70%.
Ergänzend liegt das Ergebnis erst sehr spät im Projektverlauf vor, die Phase für die QS ist kurz und somit haftet dem Importer auch noch ein großes Risiko an.
Unsere These lautet daher
In der gleichen Zeit bzw. zu geringeren Kosten ist es locker möglich, jede Seite komplett neu zu erstellen, dem Kunden ein früheres, besseres Ergebnis in höherer Qualität zur Verfügung zu stellen.
Echt? Ja echt… Nehmen wir ein Beispiel (der Importer soll sich ja auch lohnen): 500 Seiten bestehenden Content sollen neu in ein System kommen. Nehmen wir als Ausgangsbasis 500 Word-Dokumente mit Text, Bildern und Links, Verortung in der neuen Struktur und das vorgesehene Modul. Dann gehen wir bei einem – auf dem System geschulten – Redakteur von einer maximalen Bearbeitungszeit von 10 – 15 Minuten für die Neuerstellung der Seite aus, macht also was zwischen 80 und 125 Stunden und damit 10 – 15 Personentage. Da dies eine einfache Arbeit ist, reichen Hilfskräfte aus, um diesen Job zu erledigen.
Im Gegensatz dazu kostet der Importer sicherlich eine niedrige bis mittlere fünfstellige Summe, wenn alles automatisiert passieren soll. Trotzdem muss jede Seite ein paar Minuten überprüft und angepasst werden. Selbst bei 1.000 Seiten und mehr und auch bei internationalen Aufgabenstellungen bleibt die Rechnung deutlich auf der Seite der manuellen Übernahme, da die Kosten und das Risiko beim Importer bei Zunahme der Komplexität ebenfalls stark ansteigen. Dazu geht der aktuelle Trend generell weg von stark Content lastigen hin zu mehr emotional aufgeladenen Seiten. 1.000 Seiten über ein Unternehmen sind nicht zu warten, die Tochtergesellschaften in den Ländern wollen und werden sie nicht übersetzen und… tja, lesen wird sie auch niemand 😉
Und die Ausnahme von der Regel
Der Vollständigkeit halber: es gibt auch Ausnahmen, denn stark strukturierte Inhalte wie z.B. alte Pressemitteilungen können oftmals leichter importiert werden und liegen dazu noch in sehr großen Massen vor. Ob man mit diesen – redaktionell nie mehr anzufassenden – Inhalten das neue System dann belasten muss, ist von Fall zu Fall zu entscheiden.
Eine weitere Ausnahme können vielleicht Intranets und intern genutzte Wissensplattformen darstellen, die heute aber nicht Thema sind.
Wie werden Kunden zukünftig auf ein Produkt aufmerksam? Wie kann ein moderner Kaufprozess und die darauf folgende Kundenbindung aussehen? Wie werden Content Management und Customer Relationship Management Systeme zukünftig mit ERP-Systemen und dem Social Web zusammen spielen um ein modernes Kundenerlebnis zu gestalten?
Die Antworten auf diese Fragen schlummerten noch in meinen CeBIT 2013 Notizen. Dort fand der Automotive IT Congress statt, auf dem ich den Vortrag von Michael Gorriz (CIO Daimler AG) und Philipp Schiemer (Leiter Marketing Mercedes-Benz Cars) mit dem Titel “Digital-Life” – das digital-reale Mercedes-Benz Kundenerlebnis der Gegenwart und Zukunft hörte.
Mercedes-Benz-CeBIT-Kundenerlebnis
Das Ganze ist ein Orchester aus Inhalten, Kommunikations-Kanälen, Big-Data, mobilen Apps, Interaktionen und Kundenbeziehungen in einem großen Produkt-Lebenszyklus unter einem noch größeren Marken-Dach. Dabei ist es für einen Autohersteller deutlich schwieriger, ein integriertes Erlebnis aus Fahrzeugen, Funktionen und Lebensgefühl über das Web bis hin zum Händler zu transportieren, als bsw. für Amazon, die einen eindeutigen Kundenkanal anbieten, in dem sich der Kunde auch eindeutig identifiziert.
Ein neuer Kunde „entsteht“
Doch von Anfang an: Die Kundenerlebnis-Vision (die in Teilen heute bereits umgesetzt werden kann) MyMercedes startete auf Facebook. Dem Interessenten „Philipp S.“ wurde ein Foto der neuen Mercedes-Benz A-Klasse auf Facebook durch einen Freund gezeigt und auf die persönliche Pinnwand geteilt. Der Freund hatte das Bild aus der DigitalDriveStyle-App während einer Probefahrt direkt aus dem Auto geschickt.
Der Interessent klickte sich zur Mercedes-Benz Facebook-Seite und fand dort weitere Bilder und Teaser-Informationen zum Fahrzeug, das ihm tatsächlich gut gefiel. Der empfehlende Freund hatte einen Volltreffer gelandet.
Von der Facebook-Page klickte sich unser Beispielkunde zur offiziellen Marken-Homepage, die ihn nun umfassend durch CMS und Digital-Asset-Management mit allen wichtigen Produkt-Infos, Bildern, Videos und Daten versorgte. Eine erste Vorentscheidung des Kunden ist getroffen.
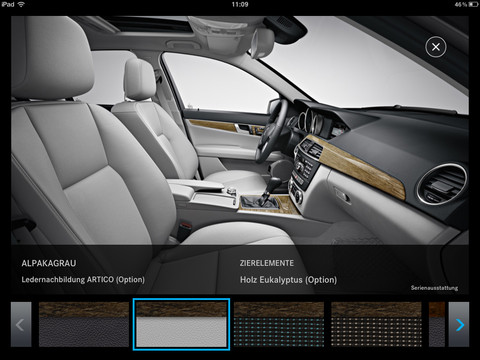
iPad Konfigurator App (c) Mercedes Benz
Von der Marken-Homepage geht es weiter in die Configurator-App auf dem iPad. Hier im modernen Fahrzeug-Konfigurator stellt sich der Bald-schon-Kunde sein Wunschfahrzeug aus aufbereiteten PIM-Daten des Herstellers bequem und ohne Zeitdruck auf dem Sofa zusammen. Die ermittelte Wunschkonfiguration des Autos wird an den nächstgelegenen Händler weiter geleitet.
Autokauf 2.0
Bei einem persönlichen Vor-Ort-Termin werden mit dem Händler Konditionen geklärt, Farben, Stoffe und Materialien final ausgewählt und eine Probefahrt vereinbart. Natürlich mit einem Fahrzeug, das der Wunschkonfiguration möglichst nahe kommt.
Nach der verbindlichen Bestellung des Autos geht es in der MyMercedes-App weiter. Direkt aus dem ERP-System des Konzerns kann der Produktionsstand in der App abgerufen werden. Sogar Fotos des baldigen Autos aus der Fertigungsanlage werden per Webcam direkt an den Kunden geschickt. Moderne Industrie-Anlagen mit direkter Anbindung an die wichtigsten Datenkanäle machen es möglich.
Ist die Produktion des Autos abgeschlossen, rückt der Auslieferungstermin immer näher.
Unser Beispielkunde möchte seine A-Klasse persönlich am Haupt-Werk in Sindelfingen abholen (Eigentlich wird die A-Klasse in Rastatt gebaut, doch Philipp S. möchte dem Mercedes-Benz Museum einen Besuch abstatten).
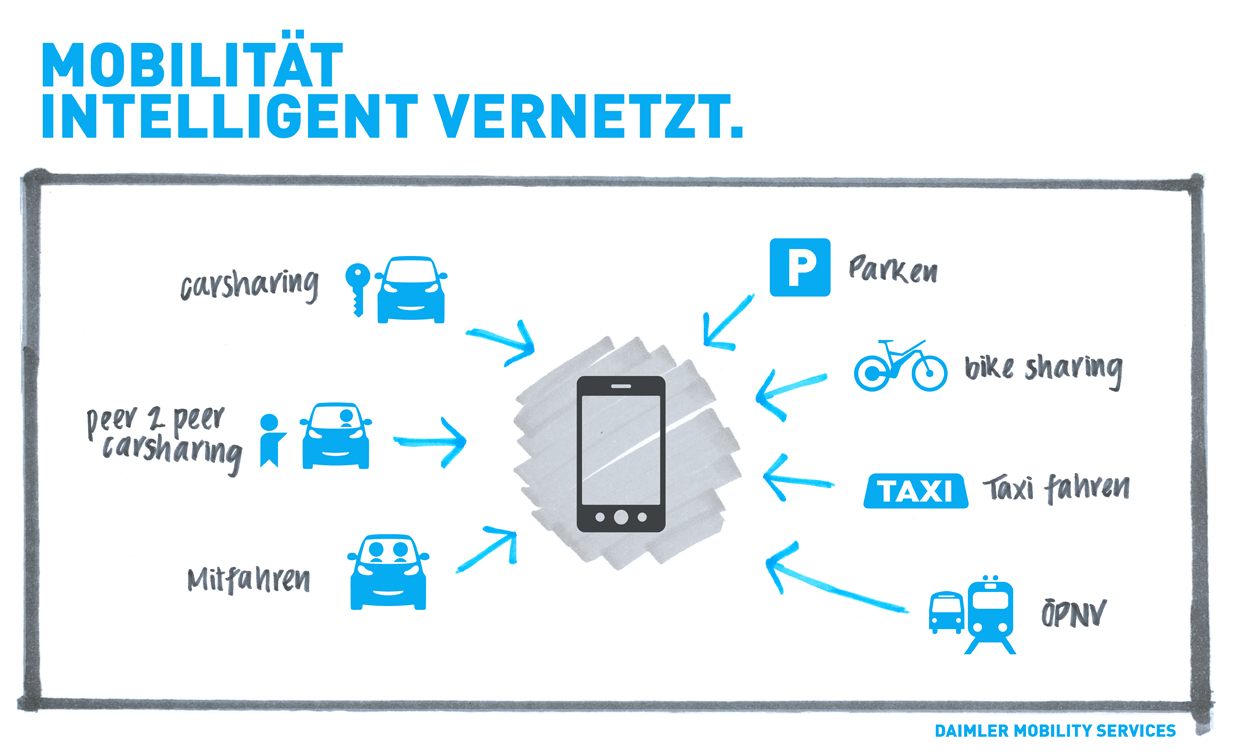
Also geht es an die Reiseplanung. Hierbei wird Philipp S. von der Moovel-App unterstützt. Moovel vereint so ziemlich jede erdenkliche Mobilitäts-Möglichkeit und baut daraus einen individuellen Reiseplan von Hamburg nach Stuttgart zusammen:
Zu Fuß zum nächsten Ca2Go smart
Mit dem smart zur S-Bahn
Mit der S-Bahn zum Flughafen
E-Tickets liegen in Moovel bereit
Während des Fluges hat Moovel eine Mitfahrgelegenheit eines ebenfalls im Flieger sitzenden Daimler-Mitarbeiter nach Sindelfingen gefunden Alternativ hätte es sonst eine Taxi- oder S-Bahn-Fahrt vorgeschlagen
Moovel Funktionsweise (c) moovel
Die erste Fahrt im neuen Auto
Natürlich hat sich Philipp S. in den Wochen vor der Auslieferung bereits intensiv mit den Funktionen und Bedienelementen seines neuen Autos befasst. Viel muss der Mercedes-Benz Mitarbeiter bei der Übergabe also nicht mehr erklären. Selbst die Sitzeinstellungen werden bereits von dem Probefahrt-Auto des Händlers übernommen.
Drive Kit plus (c) Mercedes-Benz
Eine Überraschung gibt es dennoch: Die Lieblingsmusik des Kunden wurde direkt ins Infotainment-System übertragen.
Kurz noch das Smartphone mit dem Auto vernetzen, so dass es zum Öffnen des Fahrzeugs verwendet werden kann und Philipp S. kann seine erste Fahrt im neuen Auto gen Heimat antreten.
In der DriveStyle-App werden ihm seine Facebook-Freunde entlang der Route angezeigt, sodass er sich entscheidet, auf der Rückfahrt zwei Mal von der Autobahn abzufahren und alte Freunde zu besuchen.
Eine Augmented Reality App unterstützt beim Kennenlernen des neuen Fahrzeugs. Statt Bedienungsanleitungen zu lesen, schwenkt Philipp S. mit dem Smartphone durch sein Cockpit und bekommt von der App über das Kamerabild seines Autos erklärende Zusatzinformationen angezeigt.
„Wozu ist dieser Schalter hier?“ – einfach mit der Smartphone-Kamera abfilmen und die App blendet alle relevanten Informationen ein.
Ein Jahr später. Das Kundenerlebnis geht weiter
Das erste Wartungsintervall ist rum und der Wagen muss zur Inspektion. Die MyMercedes-App erinnert an Serviceintervalle und bietet mögliche Termine beim nächstgelegenen Händler an und gleicht diese mit dem Kalender im Tablet ab.
Außerdem sieht Philipp S. in der App gleich, welche Wartungsarbeiten vorgenommen werden sollen.
Die MyMercedes-App integriert sich in den Alltag: Steht bsw. eine längere Fahrt zu einem Termin im Kalender an, erinnert die App daran, dass vor Fahrtbeginn noch getankt werden muss, da der Tank nur noch zu 1/4 voll ist.
Vor Fahrtantritt wird durch die Kalender-App die Klimaanlage gestartet und das Auto passend vortemperiert und reserviert am Zielort bereits einen passenden Parkplatz.
Und wie geht es mit dem Kunden und seiner A-Klasse weiter?
Nun, Herr Gorriz und Herr Schiemer deuteten an, dass das neue Auto unseren Beispielkunden SO sexy gemacht hat, dass nach 2 Jahren ein neues Auto für die ganze Familie angeschafft werden muss 🙂 Eine E-Klasse.
Der Clou dabei: Alle liebgewonnen Einstellungen und Features kann Phillip S. über die MyMercedes-App direkt von einem Auto ins andere transferieren.
Aus Inhalten, Unternehmensinformationen, Kunden-Daten und sinnvollen Anwendungen entsteht in diesem nicht ganz fiktiven Beispiel nicht nur ein Kundenerlebnis, sondern Kundenbindung deLuxe.
Fazit – was hat das Ganze mit comspace zu tun?
Comspace sieht sich als technischer Dienstleister an der zentralen Schnittstelle für Anwendungen dieser Art. Die Projekte, die wir realisieren setzen schon heute an unterschiedlichsten Anknüpfungspunkten einzelner Systeme unserer Kunden an. Damit realisieren wir individuelle Lösungen, in denen Inhalte aus Digital-Asset-Management, Daten aus Customer-Relationship-Anwendungen oder Artikel-Details aus Produkt-Informations-Management-Systemen herausgezogen, für den Endkunden aufbereitet und in unterschiedlichsten Ausgabekanälen zur Verfügung gestellt werden.
Diese Ausgabekanäle können verschiedensprachige Webauftritte, Intranets, zweckoptimierte Landingpages, mobile Websites und Apps oder Produktkataloge sein.
Wo immer unsere Kunden Lösungen benötigen, um komplexe Inhalte beherrschbar zu kombinieren und darstellbar zu machen, sind wir in unserem Element.
Faszinierend zu sehen, dass Unternehmen wie Mercedes-Benz heute schon darüber nachdenken, wie sie mit BigData, Kundeninformationen und Produkt-Inhalten nicht nur rein werblich arbeiten, sondern ein integriertes Kundenerlebnis schaffen, das einen echten Mehrwert bietet.
3 Tage re:publica rekapituliert man nicht mal eben so 🙂 Ich kenne keine Konferenz oder Barcamp, die ihre Gäste vergleichbar fordert, was Themenvielfalt, Konferenz-Running-Gags und die mit nach Hause genommenen Inspirationen und Informationen angeht. Das schöne ist aber, dass fast alle Vorträge als Video verfügbar sind und viele Besucher und Vortragende der re:publica nachträglich Zusammenfassungen zu ihren Lieblingsvorträgen veröffentlichen. Gut einen Monat habe ich nun gewartet um die spannendsten Vorträge sowie die Reaktionen darauf hier zusammen getragen und einen Einblick zu bieten, warum wir auf der re:publica waren und v.a. was wir für comspace von dort mitgebracht haben.
„Die re:publica hat eben auch mehr von einem Business-Festival als von einer normalen Konferenz.“
Mit diesen Worten leitete Mitorganisator Andreas Gebhard die #rp13 ein (auf seinem Blog gibt es eine lesenswerte re:publica Making-Of Serie). So wie ich mich in jungen Jahren auf Festivals auch immer daran hielt, die Bands zu sehen, die ich mir vorgenommen hatte, habe ich mich dieses Jahr zu 90% an meinen vorher festgelegten Vortrags-Plan gehalten 🙂 Trotzdem war zwischen den Vorträgen noch genug Zeit für das Netzwerken, was auf der rp13 eher einem Klassentreffen gleicht.
Panorama der großen Stage1 der Re:Publica (c) Andreas Kämmer
Neben all den Startups und dem Schwerpunktthema Afrika, Kulturthemen, netzpolitischen Diskussionen und einem durch meinen Lieblings-SfiFi-Autoren Cory Doctorow signierten Kindle der auch für mein persönliches Lieblingszitat verantwortlich war:
„I sat down with information.We talked.It confessed it doesn’t want to be free, it wants us to stop anthropomorphizing it.“ #rp13 @doctorow
…sind vor allem für die Business-Hirnwindungen die folgenden Inhalte im Gedächtnis geblieben:
Hinweis: In diesem Beitrag sind überdurchschnittlich viele Links – v.a. auf Videoaufzeichnungen der re:publica Vorträge bei YouTube enthalten. Links deswegen, weil so viele eingebettete Videos Probleme mit der Browsergeschwindigkeit bei Ihnen als Leser verursachen können.
Machen! Das Web wird auf die eigenen Server zurück geholt
Sascha Lobo ist mit seinen Vorträgen auf der re:publica mittlerweile eine feste Größe mit ebenso fester Frisur. Hat er auf einer der vergangenen re:publicas noch dazu aufgerufen wieder mehr zu bloggen und weniger der fremd-verantworteten Kanäle wie Facebook, Tumblr, Twitter usw. zu nutzen, wurde er dieses Jahr deutlich konkreter.
Mit reclaim.fm haben Lobo und Felix Schwenzel eine erste Alpha-Version einer Lösung für WordPress vorgestellt, mit der sich digital hinterlassene Spuren wie Tweets, Instagram-Bilder, Facebook-Likes, Pinterest-Pins und wie sie alle heißen, auf einer eigenen WordPress-Plattform zusammen tragen lassen. Sowohl technisch als auch (urheber-)rechtlich sind bezüglich der Nutzung von reclaim.fm noch ein paar Fragen offen. Das System das v.a. aus einigen WordPress-Plugins und Scripten besteht, verspricht aber eine echte Arbeitserleichterung zu werden. Im Auge behalten! Die zweite und noch viel wichtigere Botschaft seines Vortrags war:
Machen!
Und wenn es ein längst überfälliges Logo für das Internet ist, das Sascha Lobo mit Stijlroyal entworfen hat. Die Weltkugel von einem Netz überspannt. Dargestellt durch zwei Klammern und eine Raute:
(#)
Kleines Update nach nun ungefähr 1 Monat: reclaim.fm wurde von manchen Nutzern erfolgreich installiert. Andere (inklusive mir) waren bisher noch nicht so erfolgreich, die Plugins und Skripte zum Laufen zu bringen. Ich bin gespannt, ob von Felix und Sascha oder jemand anderem noch eine Weiterentwicklung von reclaim.fm kommt.
Content Strategie
Einen der handfestesten Vorträge mit direktem Praxisbezug habe ich von Brigitte Alice gehört. Auch wenn es in Ihrem Workshop um Content Strategy bei NGO ging (also Nichtregierungsorganisationen wie bsw. dem Roten Kreuz), lassen sich viele Ihrer Vorschläge und Ansätze auch auf die Content Strategien im Business-Bereich übertragen. Insbesondere die umfangreiche und strukturierte Recherche zur Vorbereitung, übergehend in den Content Audit, die Erstellung eines Content Inventory und die Durchführung von Content Prototyping war sehr aufschlussreich.
CRM – Constituent Relationship Management
Im Anschluss zur Content Strategie ging es direkt weiter mit dem Thema CRM. Interessanterweise immer noch im Themenfeld NGO. Deswegen sprach Fabian Schuttenberg auch von Constituent Relationship und nicht Customer Relationship. Denn auch wenn im Umfeld von Wohltätigkeits- und Nichtregierungs-Organisationen auch Beziehungsmanagement betrieben wird, ist es eben etwas anderes, ob es sich um eine Kundenbeziehung oder die zu Spendern oder freiwilligen Unterstützern handelt. Die Engagement Ladder – scheint ein hilfreiches Tool zu sein, um festzulegen, welche Conversion-Ziele gesetzt werden sollen: Vom Interessierten zum Newsletter-Abonnenten. Vom Petitions-Zeichner zum zahlenden Spender.
Raus aus der Blase Internet
Gunter Dueck hat vor 2 Jahren bereits den damals meist beachteten Vortrag der re:publica 2011 gehalten. Dieses Jahr war er eine Spur sperriger unterwegs und hat uns ganze Menschenbilder erklärt. Einigermaßen greifbar wurde das, als er vom Ethnozentrismus sprach, der sich besonders auf solchen Konferenzen zeigt. Jeder der Anwesenden kann verstehen worum es geht. Es haben nicht alle die gleiche aber doch eine ähnliche Meinung und Vorstellung von der Welt – zumindest über die Relevanz der eigenen Themen. Darüber wird oft vergessen, dass das draußen vor der Tür des Konferenzsaals im „echten Leben“ oft ganz anders aussieht. Duecks Kernaussage lautete für mich: Wir sollten empathischer sein und über den Tellerrand unserer Web-Blase hinaus blicken.
Wie wird sich Arbeit in Zukunft verändern?
Wir sind always on und damit auch immer mit halbem Kopf bei der Arbeit. Maschinen nehmen uns immer mehr Arbeit ab oder lasen uns effektiver arbeiten. Ob es nun Tablets, Apps und mobile Computing für den Wissensarbeiter sind oder Roboter, ERP-Systeme und computergestützte Logistik in der Industrie 4.0. Der zweite re:publica Tag entwickelte sich für mich zu einem Tag unter dem Überthema Arbeit:
Los ging es mit Theresa Bückers Vortrag Der Montag liebt Dich. In dem sie einen kurzen Abriss über die moderne Arbeitskultur gab. Darüber, wie wir zufriedener bei und mit unserer Arbeit sein können. Warf die Frage auf, warum die aktuellen Innovationen in Technik und Kommunikation sich eigentlich nur schleppend am Arbeitsplatz durchsetzen. Gab Beispiele dafür wie Corporate Social Responsibility auch für gute Beziehungen und Freundschaften der Mitarbeiter zuständig ist wie aber auch darauf hin, dass Arbeitnehmer selbst in der Verantwortung sind, Ihre Bedürfnisse kund zu tun, um besser Leben und Arbeit miteinander zu verbinden. Klingt ein wenig poetisch – war es in Teilen auch. Ich empfehle den Vortrag einfach anzuschauen. Ausführlicher lässt sich der Vortrag bei goodplace und schulzekopp nachlesen. Sketchnotes hat den Vortrag skizziert.
Deutlich wissenschaftlicher ging es im Anschluss mit der Soziologin Jutta Allmendinger weiter. Sie hat Lebens(ver-)läufe, ihre Einflussfaktoren und die daraus resultierenden Veränderungen nicht nur für die Arbeits-Gesellschaft untersucht. Sondern auch zwischen den Geschlechtern. Dabei hat sie festgestellt, dass sich das Gesamtarbeitsvolumen von Frauen in den letzten 30 Jahren kaum verändert hat und die Arbeitsverteilung eher unter Frauen statt fand: Von Vollzeitstellen zu mehr Teilzeitarbeitsplätzen. Damit stellte sie die These auf, dass der Heiratsmarkt im Hinblick auf die sichere Rente für Frauen derzeit noch zielführender sei als der Arbeitsmarkt. Ausführliche Beiträge hierzu bei Katrin Roenicke und bei der Bundeszentrale für politische Bildung.
Der meiner Meinung nach beste Vortrag der #rp13: Das Ende der Arbeit
Dann folgte der meiner Meinung nach beste Beitrag der re:publica 2013 (deswegen hierzu auch das Video im Text) von Johannes Kleske – seit seinem Coverfoto auf der brand:eins auch gerne der Posterboy der Digital Natives genannt 😉
Viele unserer technischen Errungenschaften dienen vor allem einem Zweck: Uns möglichst viel Arbeit abzunehmen oder leichter zu machen. Vor allem körperliche. Derzeit macht Technologie mehr Arbeit überflüssig, als sie uns neue Arbeitsplätze schafft. Deswegen sprach Johannes Kleske über Das Ende der Arbeit und wie wir in Zukunft leben wollen. Johannes zeigt historische Beispiele wie die Bürger des antiken Athen sich mit Philosophieren und Politik beschäftigten, während die Arbeit – nunja – von Sklaven erledigt wurde. Heute könnte diese Erledigung von alltäglichen Aufgaben von Maschinen übernommen werden. Kritisch beäugt er, dass arbeitende Menschen durch Maschinen natürlich auch überwacht und kontrolliert werden und führt dabei ein „Armband“ an, das Mitarbeiter der Firma Tesco während der Arbeit tragen müssen und darüber gemonitort werden.
An dieser Stelle möchte ich mal aus eigener Erfahrung betonen, dass wir bei comspace bereits eine Menge der in den oben erwähnten Ansätzen für moderne Arbeit anwenden, verinnerlicht haben und von unseren Chefs zugestanden bekommen. Seien es flexible Arbeitszeiten, Freiräume beim Arbeiten, gesunde Arbeitsplätze, Bildungsangebote usw.
Später am Tag ging es um einige Ergebnisse von Arbeit:
Autos und Mobilität
Dieter Zetsche – Daimler-Vorstandsvorsitzender (Sponsor der re:publica) wurde in einer rappelvollen Stage 1 von Martin Randelhoff interviewed und stellte sich im Anschluss einigen Publikumsfragen. Zetsche sprach über die Zukunft des Autos, autonome Fahrzeuge und das Daimler in dem Bereich bereits auf einem ähnlichen Stand wie Google ist, das vernetzte Auto und wie sich dadurch unsere Mobilität verändert. Genauso aber auch über die Integration von Social Media ins Auto und ob es Sinn macht, Facebook und Twitter während des Fahrens zu nutzen oder nicht. Eine Zusammenfassung des Interviews hat t3n und hier geht es zum Video des Interviews. Sehr empfehlenswert – zum einen, weil schon bemerkenswert ist, dass der CEO eines Konzerns wie Daimler die Re:Publica derart ernst nimmt. Zum anderen, weil interessant ist, wie die „klassische“ Industrie die aktuellen Veränderungen wahrnimmt, bewertet und mit ihnen umgeht.
Im Anschluss ging es mit einem weiteren Vortragenden aus dem Haus Mercedes-Benz weiter: Daimlers Zukunftsforscher Alexander Mankowsky hielt einen Workshop zu der Frage: „Vernetzte Mobilität – Erobert das Digitale die analogen Welten?“ – Dabei wurde klar, dass das autonome Fahren scheinbar die disruptivste und gleichzeitig ausgereifteste Technologie moderner Mobilität ist und in den nächsten 10 Jahren wohl für die meisten Innovationen sorgen wird. Alex Mankowksy erklärte, warum die Autorevolution fast 40 Jahre brauchte um richtig Fahrt aufzunehmen. Als Grund nannte er, dass zunächst die Infrastruktur mitwachsen musste: Straßen, Tankstellen, Verkehrsschilder, rechtliche Regelungen, Werkstätten und so weiter. Er zeigte Beispiele mittlerweile historischer Automobil-Innovationen, die heute aus unserem Leben nicht mehr wegzudenken sind und Innovationen die ohen Auto nie entstanden wären wie Vergnügungsparks bsw. Er gab Ausblicke auf Möglichkeiten, die sich durch selbstständig fahrende Autos ergeben: Vom Car-Sharing über Lieferdienste bis hin zu Dienstleistungen für Senioren. Bei Sketchnotes gibt es eine graphische Skizze des Workshop.
Am Rande:
In einem Workshop des Senders SWR3 kam uns die Erkenntnis: Auch Social Media Manager der öffentlich rechtlichen Sendeanstalten geben nur ungern konkrete Zahlen über Nutzer-Interaktionen in internaktiven Sendeformaten heraus.
Daten, Daten und nochmal Daten – Sammeln, Analysieren und draus lernen
Wir hatten das Thema Big Data gerade in unserem vorletzten Newsletter. Umso interessanter waren die praktischen Beiträge zu Data Science die eine Menge Fragen beantworteten:
Wie kommt man überhaupt an Daten heran?
Wie extrahiert man diese aus unterschiedlichen Datenbeständen?
Wie lassen sich diese Daten kombinieren und wieder zu neuen Informationen verarbeiten
Außerdem habe ich in dem Talk Luca Hammer endlich mal persönlich kennen lernen dürfen, der aktuell an Blognetz seiner Visualisierung der deutschen Blogger-Szene arbeitet und habe von ihm einige Path-Aufkleber abgestaubt 🙂
Der witzigste und gleichzeitig nachdenklichste Vortrag: Die Digital Natives ziehen in den Krieg
Der Vortragstitel, der mich am meisten in die Irre geführt hat. Ich dachte zunächst es geht um Digital Natives, die gegen einen großen Konzern oder eine Ungerechtigkeit Aktionen starten. Weit gefehlt!
Digital Natives sind die Menschen, die sich an eine Zeit vor dem Internet nicht erinnern können, weil sie bereits ins Internetzeitalter geboren wurden. Junge Soldatinnen sind natürlich ebenfalls Digital Natives. Was machen also Soldaten und Soldatinnen wenn sie in den Einsatz ziehen und aus Krisengebieten oder ihrer Freizeit per Facebook, Twitter, YouTube berichten? Journalist Thomas Wiegold der u.a. über die Streitkräfte bloggt (Augen geradeaus) und Sascha Stoltenow – ein ehemaliger Bundeswehr-Offizier, der nun als PR-Berater arbeitet, haben einige witzige, spannende und nachdenklich stimmende Beiträge vorgestellt und erklärt.
Und weil dieser Talk so unglaublich gut war – hier das Video, die Präsentations-Folien und ein Behind-the-Scenes-Beitrag von Thomas.
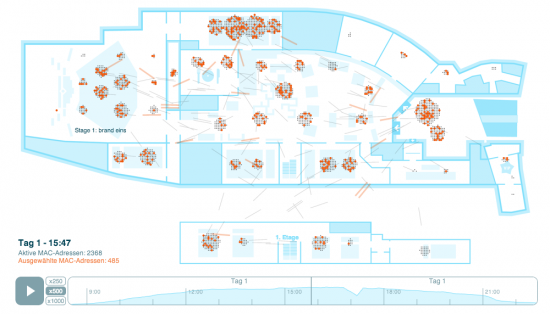
Die abgefahrenste Open Data Analyse bisher: Besucherströme der re:publica
Man nehme 5000 Konferenzbesucher, viele WLAN-Router und speichere deren Logdateien. Danach lassen sich die Bewegungsdaten durch die Säle anhand der Telefone je WLAN Router visualisieren. Un.Glaub.Lich:
Eine vollständige Wiedergabe einer solchen Mammutveranstaltung ist nur schwer möglich. Deswegen bleibe ich bei einigen Highlights, die ich erst nachher in den Videoaufzeichnungen entdeckt habe.
Maximale Performance und Ausfallsicherheit mit einem geringen Preis und minimalen Betriebskosten zu vereinen ist die Herausforderung, die jeder Infrastrukturconsultant von seinen Kunden (nahezu) jeden Tag aufs Neue von seinen Kunden gestellt bekommt. Besonders die laufenden Betriebskosten (Strom, Klimatisierung, Rack-Infrastruktur) stellen heute einen wesentlichen Kostenfaktor im Betrieb einer Serverlandschaft. Neben den Energiekosten müssen auch die Stellplatzkosten betrachtet werden – spätestens seit der bekannten Werbung des blauen Riesen („Wo sind unsere ganzen Server hin?“ – „Hier!“ – „Was ist das?“ – „Es ist ein Blade?“) ist allgemein bekannt, dass jeder das Ziel verfolgt möglichst viel Performance auf wenig Fläche unterzubringen. Denn nicht nur die Fläche, sondern auch die Anforderung an die Klimatisierung stellt eine Herausforderung dar, sobald mehr Fläche benötigt wird.
Die Lösung
Neulich stellte mich ein Kunde vor genau diese Herausforderung. Maximale Performance im Bereich der CPU-Leistung und eine hohe I/O-Rate schlossen eine Virtualisierung schnell aus, die vielen Komponenten aus denen das System bestehen sollte, sorgte schnell für eine größere Anzahl an sogenannten 2 HE-Systemen, gleichzeitig war die benötigte Anzahl an Festplatten aufgrund des geforderten Datenvolumens sehr gering, so dass wenige Festplatten zur Skalierung und Ausfallsicherheit reichten.
Der Multinode-Server der Thomas-Krenn.AG
Unser langjähriger Partner, die Thomas-Krenn.AG aus dem niederbayrischen Freyung, stellte auf der Cebit 2013 seine neuen Multinode-Systeme vor und endlich gab es einen sinnvollen Einsatzzweck. Vier vollwertige Dual-CPU-Systeme mit jeweils sechs dedizierten Festplatten auf 2 Höheneinheiten klingen sehr verlockend, immerhin können jetzt viermal so viele Systeme auf dem gleichen Raum verbaut werden. Jedes System verfügt über zwei Netzwerkanschlüsse und einen dedizierten IPMI-Port zum Remote Management, erstere können über die zusätzliche Netzwerkkarte erweitert werden. Zwei Netzteile versorgen alle vier Server redundant. Gleiche Power bei weniger Platzbedarf – war das in der IT nicht seit je her ein Garant für höhere Anschaffungskosten? Doch dann kam die Überraschung. Im konkreten Fall wurden vier RI8224M von der Thomas-Krenn.AG konfiguriert. Vom Single CPU-System mit 4 GB RAM als Proxy Server bis hin zum hochperformanten Datenbankserver mit 64 GB RAM und 2 6-Kerne-Prozessoren war alles in dem System dabei und am Ende standen ca. 30% weniger Anschaffungskosten auf dem Angebot. Betrachtete man die einzelnen Systeme im direkten Vergleich so konnten teilweise bis zu 45% der Kosten eingespart werden, selbst nach Umlage der Kosten für das Basischassis waren problemlos 40% Ersparnis möglich. Hinzu kommt die bessere Ausnutzung der Netzteile, weniger Platzbedarf im Rack und dadurch günstigere Betriebskosten – ein Traum für alle Seiten.
Der Intel Dual-CPU RI8224M ist nicht nur für komplexe Infrastrukturen für einzelne Kunden geeignet, sondern bietet auch eine gute Basis für den Betrieb von individuellen Virtualisierungs- oder Cloud-Lösungen im eigenen Rechenzentrum. Wem eine CPU pro System reicht, für den bietet der RI8316M eine ähnliche Lösung mit 8 Servern auf 3 Höhenheinheiten, die jeweils 2 Festplatten nutzen können.
Es werden nur drei Server gebraucht? Auch da gibt es eine Lösung – man nimmt das vierte Modul mit einer kostengünstigen Ausstattung und nutzt es zur Überwachung der anderen Module, denn die Serverexperten haben passend zum Linux-Tag mit TKmon ein auf der OpenSource-Lösung Icinga basierendes, intuitiv zu bedienendes Monitoringtool zur Verfügung gestellt.